

Repost artykułu z listopada, kiedy to RSS na stronie zrobił mi psikusa i przestał działać.
Oto lista 13 niezbyt interesujących ciekawostek o Google, tworzona z nadzieją że ktoś może jeszcze o nich nie słyszał. Zaczynamy!
Spis treści
1. Google i oldschoolowe rich snippety
Jeśli myślisz że rich snippety – a przynajmniej zasada ich działania – to nowość, jesteś w błędzie. Zalążków upadlania twórców treści w internecie doszukiwać się możemy w aktywnej w latach 2004-2013 usłudze Google SMS Search.
Na czym ta usługa polegała? Na niczym skomplikowanym – po prostu search przez SMS. Po wysłaniu SMSa z zapytaniem na numer 466453 (czyli G-O-O-G-L-E na klawiaturze alfanumerycznej) otrzymywaliśmy (a raczej Amerykanie otrzymywali) odpowiedź w postaci SMSa zwrotnego.
Byłaby to tylko taka sobie ciekawostka, gdyby nie jedna uwaga – SMS zwrotny nie zawierał linków do stron. Zawierał dane, odpowiedzi, informacje. Wymagał więc od algorytmu nie tyko zrozumienia treści wysłanego SMSem zapytania, ale też wyscrape’owania krótkiej, ale treściwej odpowiedzi.
Czy nie przypomina Wam to czegoś? Np. współczesnych rich snippetów często ogałacających nas z ruchu organicznego? Ich pierwotnej formy?
2. Darmowe telefony, czyli jak algorytm uczył się mowy
Serwisem podobnym do SMS Search był pozornie tajemniczo brzmiący GOOG-411. Był to automatyczny serwis telefoniczny, służący do wyszukiwania lokalnych biznesów, opierający się na rozpoznawaniu mowy.
Skąd 411 w nazwie? W USA i Kanadzie 411 to z reguły numer informacji telefonicznej. GOOG-411 był odpowiednikiem książki telefonicznej czerpiącej dane z internetu. Różnica polegała na tym, że był to serwis zautomatyzowany; rozpoznawał mowę, proponował konkretne adresy i firmy, w końcu przekierowywał rozmowę do wybranej firmy lub przesyłał SMS z jej numerem.
Usługa w latach 2007-2010 cieszyła się dość dużą popularnością, a to ze względu na fakt, że informacja pod numerem 411 była z reguły dość słono płatną usługą, natomiast numer Google był zupełnie darmowy.
Jaki interes miał w tym Google?
Wyjaśniła to (choć mam wrażenie że nie do końca to przemyślała) Marissa Mayer, dawna wiceprezes Search Products & User Experience w Google:
You may have heard about our [directory assistance] 1-800-GOOG-411 service. Whether or not free-411 is a profitable business unto itself is yet to be seen. I myself am somewhat skeptical. The reason we really did it is because we need to build a great speech-to-text model … that we can use for all kinds of different things, including video search.
The speech recognition experts that we have say: If you want us to build a really robust speech model, we need a lot of phonemes, which is a syllable as spoken by a particular voice with a particular intonation. So we need a lot of people talking, saying things so that we can ultimately train off of that. … So 1-800-GOOG-411 is about that: Getting a bunch of different speech samples so that when you call up or we’re trying to get the voice out of video, we can do it with high accuracy.
Krótko mówiąc, Google chce nauczyć się mowy. Potrzebuje więc, by ludzie do niego mówili. A gdzież będą mówić więcej, niż do słuchawki telefonu darmowej usługi, która normalnie sporo kosztuje?
3. Knol, czyli Google’owska wersja Wikipedii
Google próbował opanować chyba wszystkie aspekty internetowej aktywności, także te związane z nauką, wiedzą i przede wszystkim informacją. W 2008 roku, kiedy Wikipedii stuknęło już 7 lat i miała się całkiem dobrze, światło dzienne ujrzała beta Knola, czyli Wikipedii made by Google.
W zasadzie to mogło się udać, bo model tworzenia treści był nieco inny niż w przypadku internetowej encyklopedii Jimmy’ego Walesa i spółki. Knol oferował możliwość stworzenia wielu artykułów napisanych przez różnych autorów dla jednego zagadnienia. Artykuły kładły nacisk na punkt widzenia, a nie na neutralne, kolektywne stanowisko jak w Wikipedii.
Dodatkowo, Knol oferował opcję umieszczenia w artykule reklam Adsense, co czyniło zeń projekt nieco mniej szlachetnym i bardziej podatnym na spam i ludzką chciwość.
Projekt wzbudził kontrowersje także z tego powodu, że po raz pierwszy tak wyraźnie stawiał Google w pozycji twórcy contentu, a nie jedynie podmiotu, który treści w internecie kataloguje i organizuje.

Projekt ostatecznie zamknięto w kwietniu 2012, a pół roku później usunięto wszystkie zgromadzone treści. Dwa lata wcześniej Google przekazało Wikimedia Foundation grant w wysokości 2 mln dolarów.
4. Gdy wpakujesz się w niepotrzebną filantropię…
W latach 2002-2006 Google udostępniało organizacjom rządowym, pożytku publicznego, non profit, uniwersytetom itp. możliwość założenia specjalnego konta. Umożliwiało ono niczym nieskrępowane używanie produktów Google bez reklam. Świetnie wpisywało się to w obraz młodego, nowoczesnego przedsiębiorstwa, któremu przecież zależy nie na pieniądzach, lecz na „skatalogowaniu światowych zasobów informacji i uczynieniu ich powszechnie dostępnymi i użytecznymi”.
No cóż, gdzieś coś poszło nie tak – nie zarzucam Googlowi złej woli. Ale faktem jest, że w pewnym momencie, we wrześniu 2006 roku okazało się, że w Public Service Search (bo tak nazywała się ta funkcjonalność) istnieje jakiś – cytuję – „problem z bezpieczeństwem”.
Co robi w takim momencie multimilionowa korporacja? Na pewno nie naprawia problemu. Wrzuca na swojego bloga post, informujący o „temporary fix”, a następnie blokuje dostęp do usługi.
I za wszelką cenę stara się już nigdy o niej nie wspominać.
5. Najkrócej oferowana usługa Google
W latach 2007-2014 istniał produkt o nazwie Google Questions and Answers. Była to usługa, którą z zasady działania znamy do dziś – w takim modelu funkcjonuje np. Quora czy Stackoverflow, czyli ktoś zadaje pytanie, a internauci odpowiadają. W tłumie zawsze znajdzie się specjalista w danej dziedzinie.
Jego poprzednikiem był Google Answers (2002-2006) – dziwny twór swoich czasów, gdzie użytkownik płacił za wyszukanie informacji. Około 500 tzw. researcherów – zweryfikowanych przez Google ochotników – wyszukiwało niezbędne informacje za kwoty od $2 do nawet $200. Niesamowite, że zaledwie 13 lat temu, używanie wyszukiwarki było umiejętnością, na której można było zarobić.
Jakby tego było mało, serwis ten również miał swoją poprzedniczkę już w 2001 roku. Była to także usługa o nazwie Google Questions and Answers. Tu również można było zadawać pytania, jednak za stałą, niezmienną opłatą w wysokości $3. Odbywało się to nie poprzez stronę, lecz e-mail (!), a na pytania odpowiadali nie specjaliści, lecz zwyczajni pracownicy Google. Ktoś nie przewidział, że niewielka liczba pracowników może nie poradzić sobie z nawałem maili od żądnych wiedzy internautów.
Usługa Google Questions and Answers działała więc tylko przez ok 24 godziny.
6. Dr Google przeciwko grypie
Walka z grypą za pomocą Google to nie tylko wyszukiwanie w internecie jej objawów, które i tak – koniec końców – doprowadzi nas do wniosku że cierpimy na zaawansowany nowotwór wszystkiego.
W latach 2008-2015 Google utrzymywało usługę Google Flu Trends. Miała ona za zadanie przewidywać (a dzięki temu częściowo także przeciwdziałać) aktywność wirusa grypy w ponad 25 krajach (w tym w Polsce).
Dane zbierano na podstawie aktywności użytkowników i ich internetowych zachowań związanych ze zdrowiem; przede wszystkim wyszukiwania fraz związanych z grypą. Algorytm brał również pod uwagę numer IP wyszukującego, co pozwalało ocenić regionalność aktualnych ognisk zapalnych grypy i ich niebezpieczeństwo.
Numery IP były anonimizowane po 9 miesiącach; w obliczeniach algorytmicznych nie brali udziału ludzie a jedynie maszyny. Mimo pożytku dla zdrowia publicznego, pojawiły się głosy, że Google Flu Trends narusza prywatność użytkowników wyszukiwarki.
Według niektórych badań, Google Flu Trends potrafiło przewidzieć rozwinięcie się ogniska grypy na ok. 10 dni przed jego zgłoszeniem do stosownych władz. Wyłączając 3 bardzo przeszacowane sezony chorobowe, przewidywalność zachorowań utrzymywała się na poziomie 97%.
W samych tylko Stanach Zjednoczonych, na grypę choruje rocznie od 5 do 20 % populacji; prowadzi to do śmierci średnio 36 000 ludzi każdego roku.
7. Google to nie tylko sukcesy
Wielu internautów postrzega Google jako złote dziecko boomu internetowego, potentata skazanego na sukces. Jednak nie samymi sukcesami zapisana jest historia tego koncernu. O ile początkowe wpadki nie dziwią, to późniejsze błędne decyzje i strategie, czy produkty będące niewypałami bez siły przebicia – najzwyczajniej dziwią. Szczególnie zważywszy na fakt, jaki procent rynku internetowego kontroluje Google.
Największy i najbardziej chyba spektakularny niewypał to Google+, o którym piszę w oddzielnym akapicie. Niezależnie od innych powodów – Google+ najzwyczajniej nie sprostało wymaganiom rynku i nie nawiązało nawet sensownej walki z konkurentami pokroju Facebooka.
Najpopularniejsze profile znanych osób na G+ (Lady Gaga, Snoop Dogg, czy Madonny) obserwowało ok 8-9 mln osób, podczas gdy na Facebooku liczby te są kilkakrotnie większe.
Myślicie, że Google uczy się na błędach i nie spróbuje już social media? W produkcji jest już Google Shoelace (na razie dostępna tylko w Nowym Jorku), aplikacja do „łączenia ludzi z podobnymi zainteresowaniami”. Czyli, jak pięknie podsumowała to Matylda Grodecka na łamach Spider’s Web:
Zamiast wziąć sobie do serca przypisywaną Einsteinowi maksymę mówiącą, że szaleństwem jest robić wciąż to samo i oczekiwać innych rezultatów, Google kieruje się słowami innej znanej postaci XX wieku – Ups, I did it again.
(…)
Muszę wam wyznać, że istnieje jakaś cząstka mnie, która podziwia żelazną determinację i upór, z jakim Google wali głową w ścianę. Na razie jest co prawda jakieś 10:0 dla ściany, ale technologiczny gigant się nie poddaje.
Sądzicie, że Google+ to jedyna spektakularna porażka tego koncernu? Lista jest znacznie dłuższa:
- Google Schemer – serwis do dzielenia się i zapisywania aktywności do wykonania, w założeniu podobny do wydarzeń na Facebooku
- Google Health – usługa do gromadzenia danych o zdrowiu, lekach, alergiach itd
- Google Web Accelerator – „przyspieszacz” internetu, powodował bugi w YouTubie, szargał prywatność użytkowników
- Orkut – serwis social media powstały na długo przed G+; choć zyskał popularność w Brazylii i Indiach, nie wytrzymał konkurencji z gigantami
- Google Friend Connect, Jaiku, Google Buzz – kolejne podejścia Google do tematu social media
- Google Offers – serwis początkowo podobny do Groupon, następnie przeistoczył się w serwis z kuponami i zniżkami, zamknięty w 2014
- Google Reader – agregator Atom/RSS, zamknięty z powodu słabnącego zainteresowania
- Knol – Google’owska wersja Wikipedii, wygaszona w 2012 roku
- Nearby Notifications – narzędzie do proximity marketingu korzystające m.in. z beaconów na bluetooth – nadużywane i zabite przez spam
- Dragonfly – prototyp wyszukiwarki na rynek chiński, o którym piszę w oddzielnym akapicie
- Google Finance i Portfolios – przepis na porażkę w wykonaniu Google: zbuduj potężny produkt z myślą o inwestorach finansowych, zdobądź potężną bazę użytkowników, nie monetyzuj produktu, skasuj go bez podawania przyczyny
- Project Ara – projekt modularnego smartfonu, którego premiera zaplanowana była na 2017 rok
- Google Ride Finder – aplikacja wskazująca najbliższą taksówkę, limuzynę lub bus
- Google Moderator – crowdsourcingowy serwis do zadawania pytań i dzielenia się pomysłami, którego popularność nie spełniła oczekiwań Google
- Google Hire – usługa pomocna dla rekruterów, uruchomiona zaledwie 3 lata temu, ma zostać wygaszona we wrześniu 2020
- Google Helpouts – serwis, w którym można było uzyskać odpłatną pomoc od specjalisty w danej dziedzinie na żywo
- Google Spaces – usługa, która miała być konkurencją dla Slacka, wygaszona wiosną 2017
- Google Bulletin – usługa polegająca na przekazywaniu newsów w lokalnych społecznościach, nie wyszła z programu pilotażowego
- i wiele, wiele innych.
8. Gwóźdź do trumny Google+
Choć Google z plusem było produktem – moim zdaniem – ze wszech miar nieudanym, niska popularność nie była jedynym powodem jego wygaszenia. Choć Google’owi udało się do początku 2014 roku uzbierać aż 540 milionów użytkowników, niemal połowa pozostawała kompletnie nieaktywna. 90% wizyt w serwisie trwała mniej niż 5 sekund. Nie pomogło nawet zmuszanie m,in, współtwórcy Youtube do posiadania Google+ by skomentować swój własny filmik. W 2012 roku w badaniu porównawczym od ComScore użytkownicy spędzali w G+ średnio miesięcznie 3,3 minuty, podczas gdy na Facebooku czas ten wynosił 7,5 godziny.

Październik 2018 przyniósł informację o wygaszeniu Google+ w wersji dla użytkowników indywidualnych, co ostatecznie nastąpiło wiosną 2019. I choć wszyscy uznaliśmy to za przyznanie się do porażki i ustąpienie z wyścigu o dominację w social media, nie zawsze mówi się, co tak naprawdę było gwoździem do trumny G+.
A był to… możliwy wyciek danych. Wyciek, którego nikt nie udowodnił, który być może nawet nie nastąpił. Ale nastąpiła z pewnością możliwość wycieku, co dla decydentów z Mountain View było kroplą przelewającą czarę goryczy.
Wiosną 2018 przez 6 dni API Google+ udostępniało deweloperom prywatne dane ponad 50 milionów użytkowników. Nie ma żadnych dowodów, by ktokolwiek „skorzystał” z tego buga, ale wydarzenie to przekreśliło ostatecznie przyszłość Google+.
9. Dragonfly, czyli długa historia współpracy z cenzorem
Idee przyświecające twórcom internetu, takie jak nieograniczony dostęp do informacji, czy możliwość wyrażania swoich poglądów brzmią pięknie w ustach rzeczników prasowych, ale mieszane są z błotem, kiedy chodzi o kasę.
A kasy jest bardzo dużo na rynku chińskim, na który Google ma chrapkę. Gigant z Kaliforni był tam już obecny od 2006 do 2010 roku, serwując Chińczykom informacje przez domenę Google.cn. Oczywiście były to informacje bezwstydnie cenzurowane. Po wpisaniu frazy związanej z tematem znajdującym się na liście zakazanej przez Pekin, Google wyświetlało stosowną informację o cenzurze.

Ponieważ po 4 latach obecności na rynku chińskim, Google zdobyło zaledwie 35% tamtejszego (ówcześnie relatywnie niewielkiego) rynku, Sergey Brin przypomniał sobie nagle o prawach człowieka, wolności słowa i innych problemach, które przez 4 lata zamiatano pod dywan. Google odeszło z Chin połowicznie, przekierowując ruch na wersję Google.hk (Hong Kong), dopóki ta nie została ostatecznie całkowicie zablokowana przez Pekin. Ostatkiem sił korporacyjna hydra kurczowo łapała się swoich zarobków.
Przez niemal dekadę nieobecności Google w Chinach, tamtejszy rynek urósł o ponad 70%, a analitycy przewidują jego możliwe podwojenie. Google ostrzy więc sobie pazury na ten rynek, a robi to w sposób… no cóż, niezbyt elegancki.
Dragonfly to projekt, o którym opinia publiczna dowiedziałaby się dopiero po jego wdrożeniu, mimo, że pracowało nad nim ponad 100 inżynierów Google. Krążą pogłoski, że z prac nad tym produktem wyłączono działy prywatności i bezpieczeństwa. Nie bez powodu. Szczegóły projektu poznaliśmy tylko dzięki wyciekowi opublikowanemu na łamach serwisu The Intercept.
Dragonfly był (jest?) prototypem wyszukiwarki internetowej zaprojektowanej przez Google na rynek chiński. Kontrowersje sposobu jego działania opierają się na dwóch podstawowych zarzutach.
Po pierwsze, wyszukiwarka łączy wpisane frazy z numerem telefonu użytkownika, który daną frazę wpisał. Orwell by tego nie wymyślił.
Po drugie, wyszukiwarka nie tylko cenzurowałaby treści uznane przez Pekin za „niewłaściwe”, ale na dodatek nie informowałaby użytkownika, że właśnie oberwał po twarzy srogim batem cenzora.
W poprzedniej wersji Google.cn użytkownik wiedział przynajmniej, że dany temat jest dla rządu niewygodny i ocenzurowany – mógł więc informacji poszukać w innych źródłach. Dragonfly miał stworzyć chińskiemu użytkownikowi iluzję kraju mlekiem i miodem płynącego, niczym TVP Info w swej szczytowej formie.
Efekt? Skandal. Ponad 1400 pracowników Google podpisało się pod listem, domagającym się większej przejrzystości w pracach nad Dragonfly. Zebrano $200 000 na fundusz strajkowy dla pracowników Google – prostest miałby się rozpocząć w przypadku wdrożenia Dragonfly. Stanowczy sprzeciw Amnesty International. Stanowczy sprzeciw wielu kluczowych polityków.
W lipcu 2019, zeznając przed senacką komisją ds. sądownictwa Karan Bhatia oznajmił, że prace nad Dragonfly zostały przerwane. Co by było, gdyby nie wyciek i zaburzenie prac nad prototypem? Zapewne Google wykrajałoby sobie właśnie solidny kawał rynkowego tortu w Chinach, kosztem wolności słowa.
Google wielokrotnie zapewniało, że Dragonfly był daleki od wdrożenia, i że był to jedynie ciekawy przypadek: we felt it was important for us to explore. Jednocześnie, w upublicznionej przez dziennikarzy notce widnieje życzenie: przyszłość jest niepewna, ale aplikacja ma być gotowa w 6-9 miesięcy.
10. Kto wyniuchał sukces: wcześni inwestorzy

Jeff Bezos, jeden z pierwszych inwestorów Google
fot. Seattle City Council
Wszyscy znamy Larry’ego Page i Sergeya Brina. Niektórzy znają jeszcze być może Scotta Hassana, który właściwie sam napisał pierwszą wersję Google. Ale piorunujący sukces wyszukiwarki nie byłby możliwy, gdyby nie pierwsi inwestorzy, którzy wyczuli w uniwersyteckim projekcie olbrzymi potencjał. Kim byli?
- Andy Bechtolsheim – pierwszy poważny inwestor Google, wsparł młodych zapaleńców kwotą $100 000 zanim jeszcze zarejestrowali działalność. Bechtolsheim jest współzałożycielem Sun Microsystems, firmy odpowiedzialnej m.in. za stworzenie języka Java.
- Jeff Bezos – przedstawiać nie trzeba, twórca Amazona. Jego udziały wykupione za $250 000 w 2017 roku warte były ponad 3 miliardy dolarów
- David Cheriton – kanadyjski naukowiec i inwestor; jego czek na $200 000 dla Google przyniósł mu zwrot na poziomie ok. 1 miliarda dolarów.
- Ram Shriram – amerykański biznesmen, współpracujący wcześniej z Amazonem i Netscapem.
- Kleiner Perkins – fundusz inwestycyjny mający w portfolio udziały m.in. w Amazonie, Electronic Arts czy Twitterze.
- Sequoia Capital – fundusz inwestycyjny inwestujący m.in. w Apple, PayPal, Yahoo, WhatsApp czy Instagram.
11. Bezpieczny adres Google
Choć dziś trudno to sobie wyobrazić, niecałe 10 lat temu, aby wyszukać informację w internecie w zabezpieczonym protokole SSL, musieliśmy się udać pod specjalny adres: encrypted.google.com.
Strona ta pojawiła się w maju 2010, a branżowe serwisy opisywały ją jako „nową technologię, którą Google testuje”, choć SSL jako standard pojawił się jeszcze w latach 90.
Później sprawy potoczyły się nieco szybciej, a SEOwcy i analitycy musieli przełknąć gorzką pigułkę o nazwie not provided. Najpierw w październiku 2011 roku Google przekierował na wersję https wszystkich zalogowanych użytkowników, a w 2016 także tych niezalogowanych.
A teraz bomba: Google zachęciło webmasterów do zabezpieczania stron certyfikatami i stosowania protokołu https. Jaka jest jego siła przekonywania? Wg raportu Transparency Report, taka:
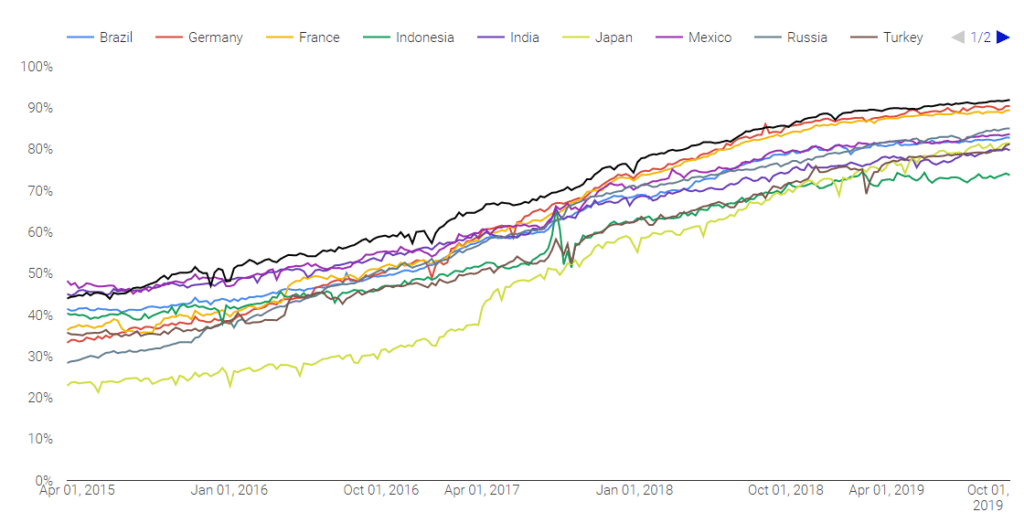
Początek listopada 2019, USA. Odsetek stron otwieranych w Chrome, używający https wynosi 92%. To robi wrażenie, wziąwszy pod uwagę, że jeszcze 3 lata temu samo Google nie wymuszało użycia zabezpieczonej wersji podczas wyszukiwania.
12. To nie konkurencja, to piaskownica
W latach 2006-2008 Google nie miało już sobie równych i było już liderem rynku wyszukiwarek internetowych. W tym właśnie czasie, inżynierowie z Mountain View zdecydowali się na dziwny krok – stworzyli konkurencyjną wyszukiwarkę SearchMash. Nie zdobyła ona oczywiście dużej części rynku, ale pewna liczba użytkowników odpłynęła z Google do nowego produktu, który – o dziwo – nie został obrandowiony, tzn. nigdzie w widocznym miejscu nie znalazła się informacja, że twórcami wyszukiwarki są pracownicy Google.
SearchMash było czymś, co dzisiaj zastępowane jest przez nieustanne testy na żywych użytkownikach – była sandboxową wyszukiwarką do przeprowadzania badań, testowania funkcjonalności i nowych pomysłów. I być może właśnie te nowe pomysły i innowacje sprawiły, że pewne grono użytkowników korzystało z owego sandboxa chętniej niż z samego Google.
To właśnie SearchMash było poligonem doświadczalnym dla wielu funkcji, które dziś wydają się oczywiste. To tam po raz pierwszy wymieszano na jednej stronie SERP wyniki z różnych kanałów: web, images, video, Wikipedia. Testowano tam infinite scroll, wyniki we Flashu, wypróbowywano różne wersje interfejsu.
Pierwszy znaczący eksperyment, jaki przeprowadzono już na żywym organizmie, po zamknięciu SearchMash było SearchWiki. Była to możliwość głosowania (a co za tym idzie – windowania w dół lub w górę) na poszczególne wyniki wyszukiwania i dodawanie do nich notatek. Dwa lata później o SearchMash, ani o SearchWiki nikt już nie słyszał.
13. Inne ciekawostki i powiązania
Pierwszą oficjalną siedzibą Google był garaż należący do Susan Wojcicki, posiadającej zarówno polskie jak i amerykańskie obywatelstwo. Susan została pierwszym managerem marketingu w Google. Obecnie jest CEO YouTube. W 2017 roku zajęła 6. miejsce w rankingu World’s 100 Most Powerful Women Forbesa. Jej siostra Anne, założycielka 23andMe (firmy tworzącej konsumenckie testy genetyczne) przez 8 lat była żoną Sergeya Brina.
A po raz pierwszy czasownika „wygooglować coś” użyto w serialu „Buffy. Postrach wampirów”.
Natomiast w 2018 roku przychód spółki Alphabet wyniósł prawie 137 miliardów dolarów, co stanowi kwotę zbliżoną do PKB Kuwejtu lub Ukrainy, jest kwotą 2 razy wyższą od PKB Bułgarii i 10 razy wyższą od PKB Armenii.
I to by na dzisiaj było tyle.
Zaufali nam

