

Od dłuższego czasu zżerała mnie ciekawość, jak duże agencje SEO radzą sobie z wdrażaniem wytycznych SEO, jakie same często zalecają swoim klientom. I dziś właśnie tę ciekawość zaspokajam, przy okazji dzieląc się z Wami wynikami mini-analizy 150 topowych stron agencji i freelancerów SEO.
Przede wszystkim chcę by było to jasne: nikomu nie wytykam błędów. Doskonale rozumiem, że w 100% odpicowana strona www nie jest w tym biznesie niezbędna. Poniższa strona również ma swoje braki.Dlatego też nie podaję adresów stron z problemami. Szanuję pracę każdego specjalisty, a błędy zdarzają się każdemu 🙂
Wiele agencji i freelancerów nie potrzebuje idealnej strony www, ponieważ:
- zlecenia pozyskują z innych źródeł – przede wszystkim z polecenia
- nie mają czasu na pucowanie strony
- szkoda im na to finansów / zasobów ludzkich
I doskonale to rozumiem. Sam nie jestem zadowolony ze stanu swojej strony, ale jak widzicie, wolę robić takie analizy jak ta poniższa, zamiast nad nią popracować.
Spis treści
Metodologia
Zacząłem od dwóch słów kluczowych służących za seedy:
- pozycjonowanie
- SEO
Z pomocą tych seedów wygenerowałem listę 210 słów kluczowych bezpośrednio związanych z tematyką SEO.
Następnie z pomocą Ahrefsa wygenerowałem listę 500 domen czerpiących z powyższych 210 słów kluczowych najwięcej ruchu (po zsumowaniu).
Z gotowej listy pobrałem topowe 150 domen agencji i freelancerów, które były obiektem badań. Ich spis znajdziesz na końcu tego posta.
Co ciekawe, ze wszystkich analizowanych 210 słów kluczowych, największej widoczności nie ma żadna z agencji, lecz Whitepress (aż 10% całego ruchu).
Co sprawdzałem?
Postanowiłem darować sobie sprawdzanie na stronach agencji elementów, które z łatwością możecie przeanalizować np. w Surfer SEO. Staram się więc unikać analizy ilości słów w title’u, czy altów w obrazkach.

Są to raczej elementy mniej charakterystyczne, czasem wymagające ręcznego sprawdzania, mam nadzieję, że dość ciekawe.
Na początek: śmieci w indeksie
Na początek wartościowy tip dla początkujących webmasterów. Jeśli wrzucimy na swój serwer (np. używając WordPressa) jakikolwiek plik (np. obraz lub PDF), to fakt, że nigdzie nie wstawiamy do niego odnośnika, NIE oznacza że plik ten nie znajdzie się w indeksie Google.
Wrzucanie poufnych dokumentów na ogólnodostępny serwer nie jest więc najlepszym pomysłem.
Oczywiście różny jest stopień poufności znalezionych przeze mnie dokumentów.
Najczęściej są to szablony. Szablony raportów, szablony audytów, szablony umów, szablony ofert… Bardzo prosty sposób na bezsensowne udostępnianie swojego know-how.

Stopień zagrożenia w tym wypadku nie jest oczywiście duży, ale znając realia tej branży, z łatwością znajdzie się ktoś, kto właśnie zakłada „agencję SEO”, ale z natury jest leniwy i z chęcią przytuli taki szybki, darmowy szablonik.

Inna kwestia to dokumenty otrzymane od klientów, będące częścią tworzonej lub pozycjonowanej przez agencję strony – zwykle niepoufne, ale za to dające jasną informację, z kim agencja współpracuje. Czasem są to informacje, które agencje – a zwykle także i klienci – wolą utrzymać w tajemnicy.
Tu znalazłem trochę dokumentów m.in. z branży prawniczej i farmaceutycznej, które z wiadomych względów, raczej współpracą z agecjami marketingowymi chwalić się nie chcą
Zdarzają się też żarty 🙂

… a także:
- „Instrukcja BHP przy obsłudze betoniarki”,
- dokumentacja techniczna „Termostatycznych zaworów rozprężnych”,
- podanie o przyjęcie do przedszkola,
Czyli międzybranżowa dywersyfikacja działań w pełnym rozkwicie 😉
Robots.txt i co blokujemy
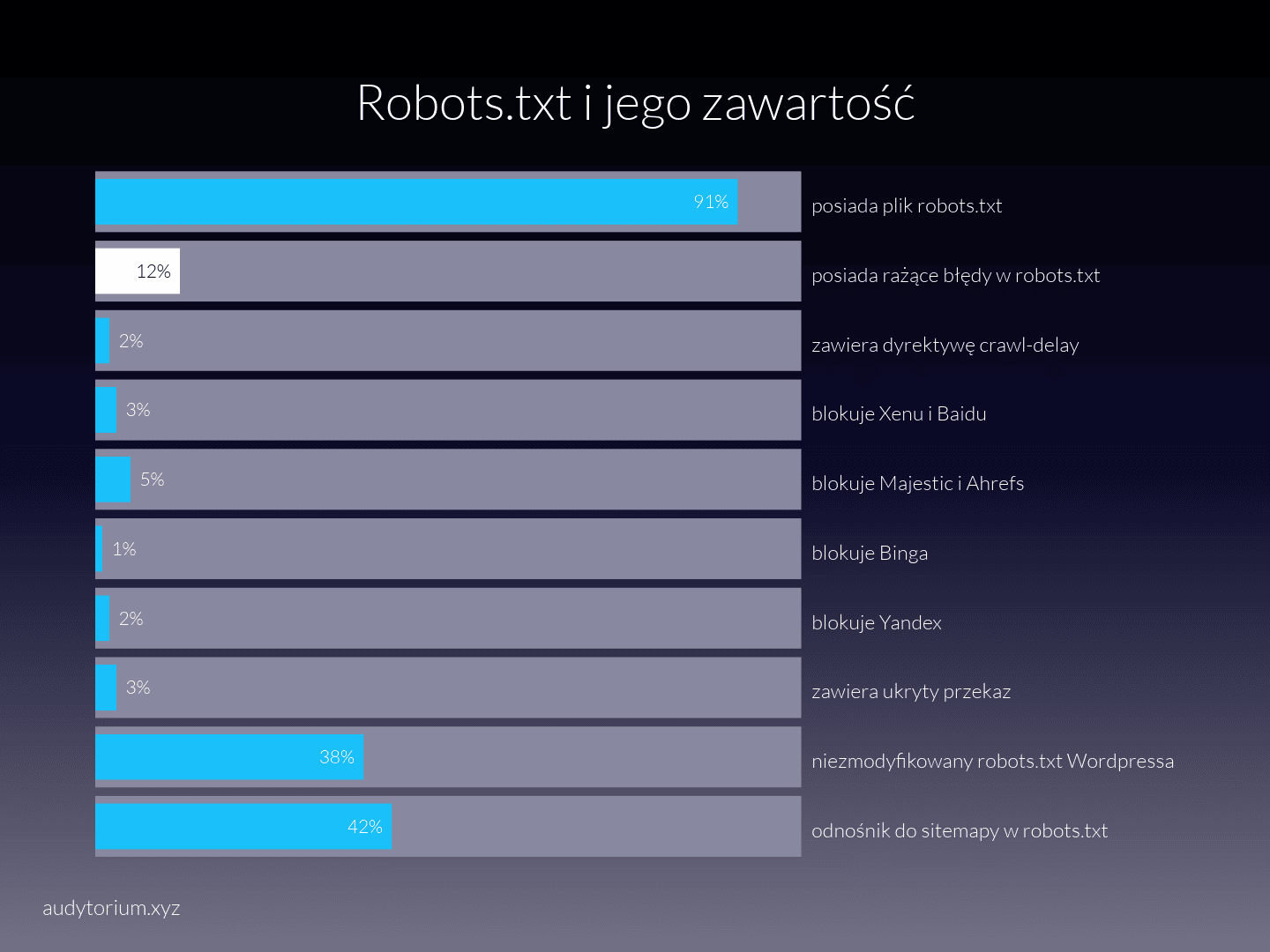
Aż 9% stron agencyjnych nie posiada pliku robots.txt. Wbrew pozorom nie jest to takie złe – wiele z agencji, które plik posiadają, trzyma tam bezsensowne komendy typu:
User-agent: * Allow: /
No cóż, protokół REP nie jest jeszcze do końca ustandaryzowany, ale wpis tego typu kompletnie mija się z celem, jaki przyświecał twórcy pomysłu na plik robots.txt.
2% analizowanych stron zawiera respektowaną przez nieliczne roboty dyrektywę crawl-delay, która w ma skuteczność porównywalną do homeopatii w czopkach – czyli nie działa i jest niezbyt przyjemną stratą czasu. Ale też nie szkodzi.
42% analizowanych plików zawiera odnośnik do mapy lub map witryn, co na tle niektórych statystyk jest wynikiem niezłym, ale nadal zastanawiającym.
Przejdźmy do blokowania botów, bo to również ciekawe. I tak, cel blokowania Majestica i Ahrefsa na stronie firmowej pozostaje dla mnie tajemnicą. Również blokowanie Baidu i Yandexa – jeśli robimy to z oszczędności zasobów serwera, to znaczy to, że stanowczo czas zmienić serwer na lepszy.
Mamy też jedną stronę blokującą dostęp robotowi Binga. Być może jest to jakaś celowa strategia – nie oceniam.
Aż 12% przebadanych stron ma w pliku robots.txt rażące błędy.
„Rażące”, tzn. mogące negatywnie wpłynąć na indeksację witryny, lub co najmniej zawierające bezsensowne komendy.
Przykłady?
- blokowanie wszystkich arkuszy .css
- blokowanie folderu z plikami .js, które mają istotny wpływ na treść na stronie
- dwa odnośniki do map witryny: z http i https
- blokowanie całego folderu wp-content na WordPressie (a więc także uploadowanych grafik)
Dużo jest również bezsensownych plików, które istnieją bez wyraźnego celu, choć też stronie nie zaszkodzą, np.:
User-Agent: * Allow: /
ale również odwrotnie 🙂 :
User-agent: * Disallow:
Niektórzy w ogóle postanowili pozostawić robotom pole do domysłu (oto cała zawartość robots.txt):
User-agent: *
Zdarzają się też tacy, którzy poświęcili dużo czasu na wykoszenie ruchu z niepożądanych miejsc, a później wpuścili tam Googlebota – mam wrażenie, że nie o to tu chodziło:
User-agent: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/plugins/ Disallow: /wp-content/cache/ Disallow: /wp-content/themes/ Disallow: /trackback/ Disallow: /feed/ Disallow: /comments/ Disallow: /category/*/* Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /*? Allow: /wp-content/uploads/ User-agent: Googlebot Allow: /
Są to oczywiście drobne błędy i przypominam że czepiam się ich tylko w ramach ciekawostki.
4 z analizowanych stron przekazuje nam także w pliku robots.txt swój ukryty przekaz.
Np. Cyrek Digital:

# # Oooooo widze, ze zajrzales i tutaj ... czyzbys byl zboczonym losiem branzowym ? # A moze szukasz natchnienia ? # A moze analizujesz moje smieciowe backlinki ? # # Jesli tylko przypadkiem tutaj wszedles napisz mi o tym :) # # Pozdrawiam grzebiacych :) #
… czy jeszcze inna strona, której nie zaprezentuję, bo na 5 prób 5 razy ich serwer odmówił współpracy.
No cóż, niektórzy w robots.txt zamieszczają też ukryty przekaz, który jest nieco mniej zamierzony:
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /logowanie/
Disallow: /zaplecze/
Przezorny zawsze ubezpieczony, dlatego proponuję jednak zdjąć to z robots.txt, bo złych ludzi w tej branży nie brakuje.
SSL, www i przekierowania
98% analizowanych stron posiada wdrożony certyfikat SSL. Wynik bardzo dobry.
Niestety, fakt, że certyfikat istnieje, nie oznacza, że został poprawnie wdrożony. Czy nie zapomnieliśmy o przekierowaniach?
Niestety, to zdarza się nawet najlepszym.

21% stron fachowców ma więc problemy ze zdecydowaniem się, która wersja im się najbardziej podoba. Lub po prostu temat olano 🙂
Serwis shakowany? No problem
Wśród 150 badanych serwisów udało mi się znaleźć również jeden shakowany – lub dochodzący do siebie po shakowaniu. W każdym bądź razie, w indeksie wciąż jeszcze mamy dużo dalekowschodniego alfabetu:

Biorąc pod uwagę metodologię doboru domen do poniższego badania, fakt, że mamy / mieliśmy włam na domenie nie przeszkadza wcale w dobrym rankowaniu w trudnej branży.
Zaindeksowane subdomeny
Przeanalizowałem również ilość i rodzaj zaindeksowanych subdomen.
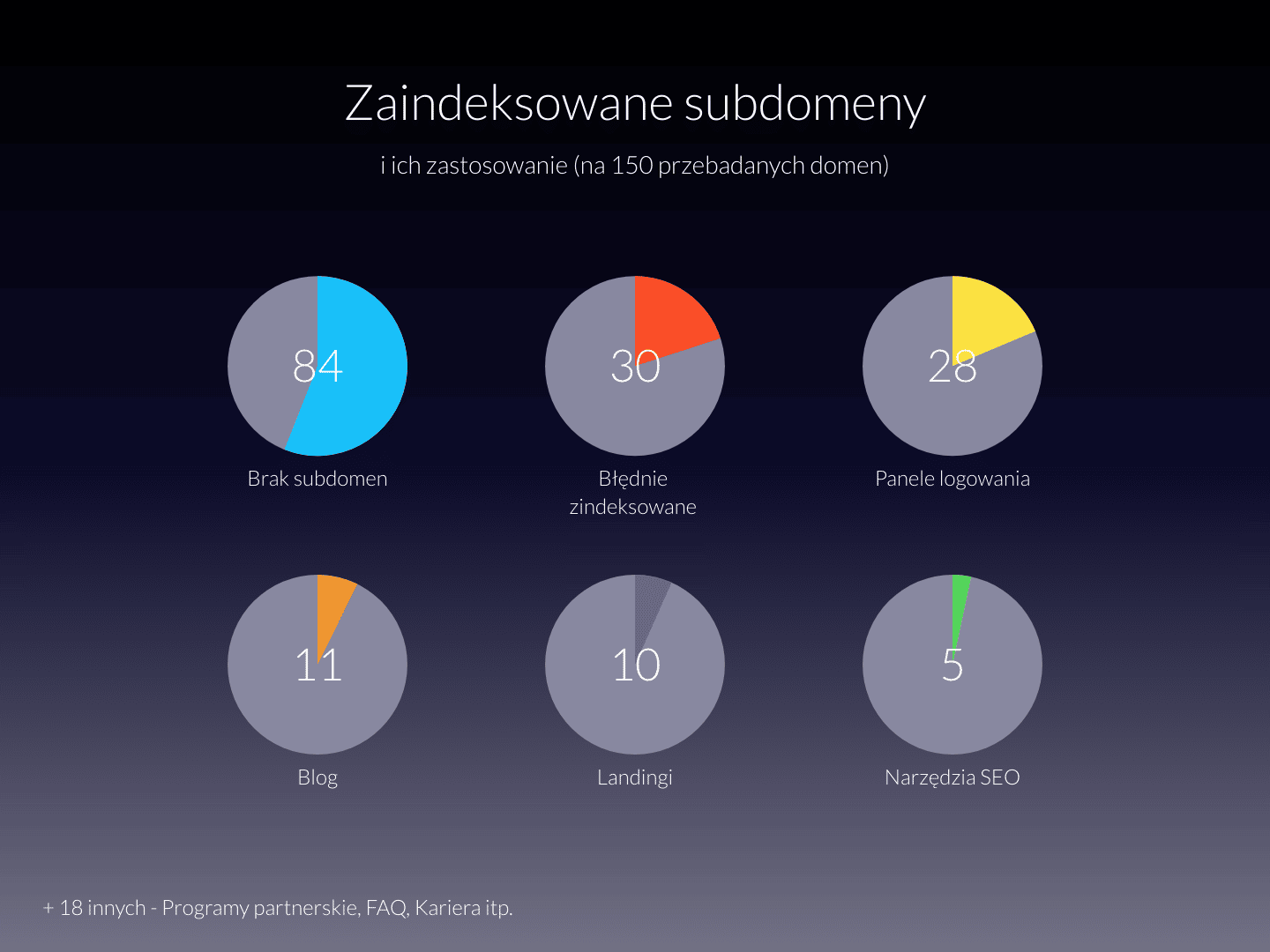
Dane te oczywiście niewiele mówią o faktycznych składowych danych witryn – są to tylko te elementy, które, z jakichś powodów, wyciągnięte zostały poza główny serwis.
Więcej mówi nam fakt, że w obrębie 150 badanych domen, aż 30 miało jakieś błędy lub problemy z indeksacją subdomen. Zaliczały się do nich między innymi:
- duplikacje www. i bez www. w obrębie subdomen
- bardzo liczne zaindeksowane wersje deweloperskie
- stare wersje stron, pozostawione w subdomenie w sumie nie wiadomo po co
- dużo subdomen wyświetlających strony…hmm, klientów? (potężna duplikacja)
- i w końcu bardzo popularny problem: losowe znaki wpisane jako nazwa subdomeny dają kod 200, ba, czasem nawet wyświetlają dziwne strony 🙂
Przegląd subdomen agencji SEO to prawdziwa kopalnia złota dla szpiegów gospodarczych. Lub osób chcących dowiedzieć się, kto komu robi SEO 🙂Śmiesznie przestaje być w momencie, kiedy gdzieś w indeksie znajdują się zagubione ankiety medyczne (na szczęście niewypełnione), specyfikacje zleceń – dokumenty, które raczej nie powinny ujrzeć światła dziennego.
Losowe znaki wpisane jako nazwa subdomeny, zwracające kod 200 to problem w przypadku… 40 stron na 150 przebadanych. Nawet strony znanych osobistości w tej branży, są na to podatne.
Potrafię sobie wyobrazić sytuację, w której ktoś z konkurencji odnajduje ten problem, a następnie przykłada się do tego, by stworzyć Wam problem z duplikacją treści.
W niektórych przypadkach losowa subdomena wyświetli tylko stronę logowania Pleska, czasem jest to pusta strona z kodem 200, innym razem sprytny odnośnik wepchnięty przez rejestratora domeny lub hosting. Ale w zdecydowanej większości będzie to strona główna serwisu, co może być najbardziej problematyczne.
Są też inne przypadki, np. gdzie agencja będąca częścią większej grupy, pod zaindeksowanymi subdomenami wyświetla kopie innych stron z tej samej grupy. I owszem, zapewne canonical załatwi ten problem, ale niesmak jest.
Skala duplikacji stron klientów, na skutek błędnej delegacji DNS na serwerze jest prze-ra-ża-ją-ca. Pod subdomeną xxx.domena.pl wyświetla się strona klienta lub po prostu sklep mający niefart dzielić z agencją SEO shared hosting. Teoretycznie taka duplikacja treści nie musi… ale może zjeść taki sklep na śniadanie. Tzn. zniszczyć go.
Aby przekonać się, jaka jest skala problemu w kwestii niepotrzebnie zaindeksowanych subdomen, wystarczy wpisać w Google dla wybranej domeny:
site:*.domena.pl
… a następnie stopniowo odsiewać nieinteresujące nas subdomeny dodając do zapytania operatory:
-site:www.domena.pl -site:blog.domena.pl itd.
Lorem ipsum…
Dość powszechne na stronach agencji jest pozostawianie w indeksie niedoróbek w postaci pustych stron, wypełniaczy i domyślnej treści szablonów. Trudno tu dokładnie kwalifikować co można, a czego nie można zaliczyć do „niedoróbek”. Łatwiej jest zmierzyć coś innego.
Aż 26 ze 150 badanych stron (17%) ma w obrębie domeny zaindeksowane słowa Lorem Ipsum w charakterze wypełniacza.
Co więcej, zdarza się to nie tylko na zapomnianych podstronach, ale nawet na stronach zamówień i stronach ofertowych.
Można dostać oczopląsu, prawda? Wszystko to screeny z analizowanych stron, pełnych „loremów ipsumów” i „I am text blocków”.
Test optymalizacji mobilnej
2020 rok, czas chyba ruszyć zadek i dostosować stronę do wymogów urządzeń mobilnych. Brzmi kuriozalnie? A jednak, nie wszystkie agencje SEO i freelancerzy o to zadbali.

Badałem tylko strony główne, oficjalnym narzędziem Google. Fakt, że test Google nie został oblany, nie oznacza, że strona wygląda dobrze na mobile. Oznacza tylko, że nie ma na niej elementów zbyt blisko siebie, określono viewport itd.
Problemy z renderowaniem
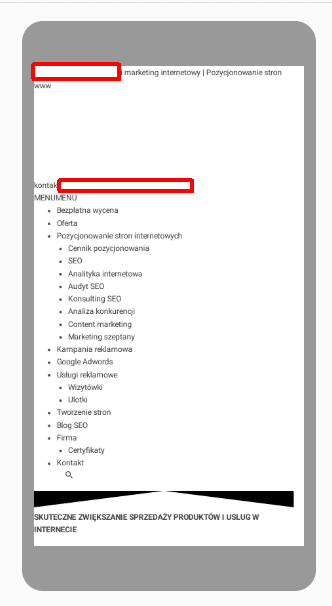
Taki widok to dla robota Google nie rzadkość. Dlaczego? 150 przebadanych witryn zablokowało przed robotem Google w sumie 2195 zasobów.
Samo blokowanie oczywiście nie zawsze jest błędem, ale często „z rozpędu” zablokowano np. arkusze CSS lub istotne pliki .js i efekt jest taki jak powyżej.
Jeszcze ciekawiej prezentują się statystyki błędów w konsoli Chrome. Na 150 przebadanych stron, 95 wysypuje w konsoli błąd na stronie głównej. W porządku, niech pierwszy rzuci kamieniem, kto choć raz w życiu nie zignorował takich błędów.
Problem pojawia się jednak u rekordzistów. Jedna z badanych stron może się pochwalić wyśmienitym wynikiem 97 błędów w konsoli – i to na samej tylko stronie głównej. Osiągnięcie takiego wyniku to wcale nie łatwe zadanie 🙂
Nagłówki H1
Tu raczej w ramach ciekawostki – jakimi hasłami zawartymi w H1 reklamują się agencje na swoich stronach głównych:

Dodatkowo, 14 z badanych stron ma na stronie głównej podwójne (co najmniej) nagłówki H1. Nie uważam tego za szczególny błąd, ale często te same agencje nakazują klientom trzymać się tylko jednej H-jedynki.
Znacznie gorzej świadczy o niektórych agencjach fakt, że nagłówki traktowane są jako sposób na formatowanie wizualne tekstu. Ich potencjał semantyczny jest kompletnie zaprzepaszczany.
Kopiuj, wklej, nie sprawdzaj
Bardzo często w kodzie stron widać treści przeklejone z wszelkiej maści Wordów i innych edytorów tekstu, wraz z całym dobrodziejstwem inwentarza. Czyli masą niepotrzebnego, śmieciowego kodu.
Niektórzy webmasterzy podnieśli jednak w tej kwestii poprzeczkę używając wtyczki do Chrome o nazwie LanguageTool służącej sprawdzaniu pisowni.
Ta niezwykle upiększa kod, dzięki czemu zamiast prostego:
<strong>Pozycjonowanie stron www</strong>. SEO (ang. Search Engine Optimization) to szereg działań i mających na celu poprawę widoczności strony marki klienta w wyszukiwarkach.
…mamy:
<strong>Pozycjonowanie stron www</strong>. <span class="hiddenSpellError" onkeypress="MORFOLOGIK_RULE_PL_PL---#---null---#---Wykryto prawdopodobny błąd pisowni---#---Sen#Sto#SED#Sek#Set#SEM#Sio#Deo#Sęp#Seto#Eo#Seko#Sęk#Leo#Meo#Reo#SKO#SO#SWO#Se#See#Sego#Sem#Sex#Sep#Ser#Śmo---#---SEO">SEO</span> (ang. <span class="hiddenSpellError" onkeypress="MORFOLOGIK_RULE_PL_PL---#---null---#---Wykryto prawdopodobny błąd pisowni---#---Serach---#---Search">Search</span> Engine <span class="hiddenSpellError" onkeypress="MORFOLOGIK_RULE_PL_PL---#---null---#---Wykryto prawdopodobny błąd pisowni---#------#---Optimization">Optimization</span>) to szereg działań <span class="hiddenSpellError" onkeypress="MORFOLOGIK_RULE_PL_PL---#---null---#---Wykryto prawdopodobny błąd pisowni---#------#---on-page">on-page</span> i <span class="hiddenSpellError" onkeypress="MORFOLOGIK_RULE_PL_PL---#---null---#---Wykryto prawdopodobny błąd pisowni---#------#---off-page">off-page</span> mających na celu poprawę widoczności strony <span class="hiddenGrammarError" onkeypress="CUDZYSLOW_DRUKARSKI---#---4---#---W tym miejscu powinien być typograficzny cudzysłów <br/>otwierający: '„'.---#---„---#---"">„</span>marki<span class="hiddenGrammarError" onkeypress="CUDZYSLOW_DRUKARSKI---#---2---#---W tym miejscu powinien być typograficzny cudzysłów <br/>zamykający: '”'.---#---”---#---"">„</span> klienta w wyszukiwarkach.
I tak aż do końca strony…
Nieśmiertelne display:none
Kiedy na grupkach SEO widzę porady, by niepotrzebne elementy strony „usuwać” za pomocą display:none, wyobrażam sobie, jak Håkon Wium Lie, pomysłodawca CSS, łka z bezradności i wyje do księżyca.
Nie jest to dobry pomysł na „usuwanie” treści, ponieważ sposób ten żadnej treści nie usuwa. Tym bardziej powinni o tym wiedzieć SEOwcy i nie używać go do usuwania linków, np. do nieistniejącego już od dłuższego czasu Google Plus.
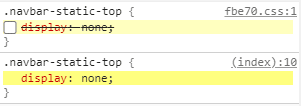
Reasumując – nie ma się co czepiać…
Cały ten post wygląda jak jedno wielkie przyczepianie się do pierdół. Niestety, ale wiele z badanych stron prezentuje żałosny poziom techniczny i dopuszcza się czasem niewybaczalnych błędów.
Jednocześnie inne są strony są świetne, a cała masa prezentuje średni, poprawny poziom techniczny z pojedynczymi problemami i błędami.
Do innych, pomniejszych ciekawych grzeszków należą między innymi:
- użycie w kodzie komend googleoff i googleon, które działały tylko na urządzeniu Google Search Appliance i nigdy nie były obsługiwane przez robota Google
- usuwanie starych ofert poprzez wykomentowanie ich w HTML, dzięki czemu wciąż możemu przeczytać o zaletach katalogowania stron 🙂
- używanie wycofanych tagów html takich jak font czy center, oraz atrybutów.
Należy jednak pamiętać, skąd wziąłem listę stron do analizy. To są strony dzielące się w polskim Google największym ruchem organicznym na słowa związane z pozycjonowaniem. Czyli ostatecznie strony te rankują, działają i nieważne jakie problemy techniczne je dotykają. Nie ma się więc co czepiać.
Jest oczywiście pewien zgrzyt między tym, co agencje rekomendują do wdrożenia swoim klientom, a tym, co same prezentują na swoich stronach. Nie potrafię jednak stwierdzić, kiedy wynika to z niewiedzy, a kiedy po prostu z faktu, że strona nie jest priorytetowym kanałem sprzedaży i traktuje się ją po macoszemu.
…a może jednak?
Bardziej smuci fakt, że kuleje zawartość merytoryczna niektórych z tych stron.
Wykwalifikowani specjaliści naszej firmy zapewniają kompetentną oraz komfortową współpracę dającą gwarancję osiągnięcia założonych celów.
Dobrze dobre słowa kluczowe [sic] przed rozpoczęciem pozycjonowania strony, to gwarancja zwiększenie ruchu na stronie.
Chcesz mieć pewność, że za 6 miesięcy podwoisz bezpłatny ruch w e-sklepie?
Faktura VAT | Kilkanaście lat doświadczenia | Gwarancja efektów
Podejmując współpracę z ******** otrzymujesz gwarancję skutecznego pozycjonowania
Cóż, lata starań w temacie edukacji klientów psu na budę.
Lista przebadanych domen
Niestety, listy nie będzie, ponieważ dostałem już pierwsze groźby zawierające słowa "kancelaria". Przypominam, że lista zawierała 150 najbardziej widocznych domen, które przebadałem. Tylko tyle. Świat schodzi na psy.
Zaufali nam


Chce dofollow! Jak można nie dać linka 😉
Niedopatrzenie, które już zostało naprawione 😉
Kurczę dziena! Nie spodziewałem się 😀
Jak to mówią, szewc bez butów chodzi 🙂 niezły hardcore, chciało Ci się analizować i głowa nie rozbolała.
PS Dobrze, że mniejszych stron nie badałeś 🙂 Na moich stronach jest coś, co tylko 0,001% stron na świecie ma prawidłowo zaimplementowane 😉
Świetnie napisany artykulik 🙂 coś innego niż u wszystkich, ale cała prawda taka działa SEO..
To niestety sama prawda. Rok temu byłem klientem agencji i to była masakra. Z hasłem SEO na ustach sprzedawali po prostu ściemę i zero kompetencji. Dlatego wziąłem sprawy w swoje ręce. Ostatnio robiłem analizę serwisu ewidentnie sztucznie pozycjonowanego metodami sprzed 10 lat. Numerki SEO się teoretycznie zgadzały, Top 3 po prostu wymiata, 12 kilo linków dofollow ale takich, że Trust Rank ledwo od ziemi odstawał… A marketing w Firmie nie wie co jest nie tak, bo agencja od SEO robi świetną robotę…