MREID (Machine-Readable Entity IDs), czyli jak Google rozumie świat
20 kwi
Nie wiem, czy Cię to zdziwi, czy nie, ale Google prawie każdemu elementowi znanego mu świata nadał unikalne ID. Dziś trochę o tych unikalnych numerkach, o których – nie wiedzieć czemu – w świecie SEO niewiele się mówi.
Niemal każda duża firma, znana osobistość, zwierzę, roślina, wynalazek, zjawisko, film, dzieło artystyczne, wydarzenie, organizacja, ideologia… prawie wszystko, o czym możesz przeczytać w internecie ma swój numer. Ba, ma nawet kilkadziesiąt numerów i oznaczeń nadawanych przez różne ciała i organizacje, ale nas siłą rzeczy interesuje oznaczenie, jakim posługuje się Google.
Znacie aktorkę, Anne Hathaway?
fot. z lewej: ONU Brasil
To ona po lewej. Po prawej prawdopodobnie jedyny zachowany rysunek innej Anne Hathaway, żony Szekspira.
Skoro obie panie nazywają się dokładnie tak samo, skąd Google ma wiedzieć, o której z nich właśnie napisaliśmy artykuł? Moglibyśmy oczywiście uzupełnić dane strukturalne i np rozpisywać się w nich o filmach w jakich wystąpiła aktorka, nagrodach jakie otrzymała itd. Ale czy nie prościej byłoby skojarzyć nasz artykuł z wiedzą na temat tych Pań, jaką Google już posiada?
Spis treści
MREID a Google
Tutaj na scenę wkracza coś, co umownie nazywamy MREID, czyli Machine-Readable Entity ID, czyli „ID jednostki czytelne dla maszyn”. W dokumentacji API Google, jest to po prostu ID lub KGID (Knowledge Graph ID).
Jest to unikalne ID nadawane jednostkom informacji i wykorzystywane w wielu produktach w całym ekosystemie Google – w Searchu, Image Search, Google Trends i wielu innych.
Anne Hathaway, która jest aktorką, w oczach Google jest więc /m/02vntj, a żona Szekspira znana jest pod pseudonimem /m/03mzbg. Prawda, że uroczo?
ID tego typu nadawane jest w tak wielu dziedzinach, że trudno pokusić się o wymienianie. Wszystkie dzieła, książki, filmy, znani ludzie, zespoły, wydarzenia, znane organizacje, duże firmy, wydawnictwa, drużyny sportowe, gry wideo, seriale, wydarzenia historyczne, partie… wszystkie te jednostki wiedzy mają swoje unikalne ID.
Jak znaleźć interesujący nas MREID?
Sposobów na to jest wiele.
Wikidata
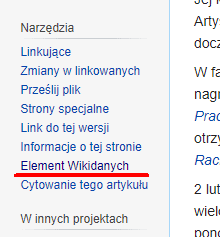
Najprostszy, acz niekompletny to serwis Wikidata. Możesz bezpośrednio w serwisie wyszukiwać interesujących Cię pozycji, lub – jeśli uznasz to za wygodniejsze – klikać stosowny odnośnik przy każdym artykule na Wikipedii.
Interesujące Cię ID znajdziesz pod hasłem Freebase ID:
Przy okazji – ostatnio na jednej z facebookowych grup SEO napotkałem pytanie o narzędzie, które dla listy słów kluczowych dobierze kategorie, powiązane tematy itp. Wrodzona nieśmiałość i lenistwo sprawiły, że nie odpowiedziałem, ale Wikidata i trochę XPath-a to odpowiedź na ten problem 😉
Google Trends
Bardzo prostym sposobem jest również użycie Google Trends. Wystarczy wpisać interesujące Cię hasło i poczekać na podpowiedź od Google:
Po kliknięciu, MREID pojawi nam się w adresie URL:
Oczywiście pasek adresu wyświetla nam wersję zakodowaną procentowo: %2F to oczywiście slash /
{
"@context": {
"@vocab": "http://schema.org/",
"goog": "http://schema.googleapis.com/",
"resultScore": "goog:resultScore",
"detailedDescription": "goog:detailedDescription",
"EntitySearchResult": "goog:EntitySearchResult",
"kg": "http://g.co/kg"
},
"@type": "ItemList",
"itemListElement": [
{
"@type": "EntitySearchResult",
"result": {
"@id": "kg:/m/0dl567",
"name": "Taylor Swift",
"@type": [
"Thing",
"Person"
],
"description": "Singer-songwriter",
"image": {
"contentUrl": "https://t1.gstatic.com/images?q=tbn:ANd9GcQmVDAhjhWnN2OWys2ZMO3PGAhupp5tN2LwF_BJmiHgi19hf8Ku",
"url": "https://en.wikipedia.org/wiki/Taylor_Swift",
"license": "http://creativecommons.org/licenses/by-sa/2.0"
},
"detailedDescription": {
"articleBody": "Taylor Alison Swift is an American singer-songwriter and actress. Raised in Wyomissing, Pennsylvania, she moved to Nashville, Tennessee, at the age of 14 to pursue a career in country music. ",
"url": "http://en.wikipedia.org/wiki/Taylor_Swift",
"license": "https://en.wikipedia.org/wiki/Wikipedia:Text_of_Creative_Commons_Attribution-ShareAlike_3.0_Unported_License"
},
"url": "http://taylorswift.com/"
},
"resultScore": 4850
}
]
}
Kod SERPa
MREID możesz również poznać zaglądając w kod źródłowy SERPa, na którym wyświetla się knowledge graph z interesującym Cię zagadnieniem.
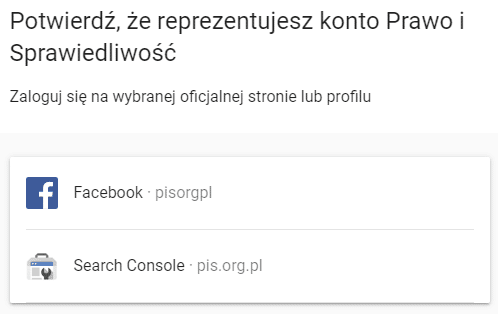
MREID w kodzie wyświetla się kilkakrotnie, ale najłatwiej jest go znaleźć jeśli pod knowledge graphem wyświetla się przycisk „Zgłoś prawo do tego panelu wiedzy”.
Odnośnik tego przycisku prowadzi do strony:
https://posts.google.com/claim/?mid=/m/02vntj
… co daje nam gotowy MREID.
Swoją drogą, warto kliknąć ten przycisk z czystej ciekawości. Można się na przykład dowiedzieć, kto pofatygował się by założyć sobie Google Search Console 🙂
Inne
Do MREIDs można dotrzeć na kilka innych sposobów, ale myślę, że przedstawiłem wystarczająco dużo metod. Inne obejmują dalsze grzebanie w kodzie stron Google, stworzenie sobie skrypu JS, który wyświetli MREID w konsoli, lub np. użycie stron z dumpami Freebase jak np. ta.
Właściwość ta jest przez webmasterów oznaczana bardzo rzadko, a jeśli już, to ogranicza się do wskazania stosownej strony na Wikipedii.
Tymczasem nic nie stoi na przeszkodzie, by dane strukturalne w formacie JSON-LD zawierały tablice; wskazanie więcej niż jednej właściwości sameAs nie jest więc problemem.
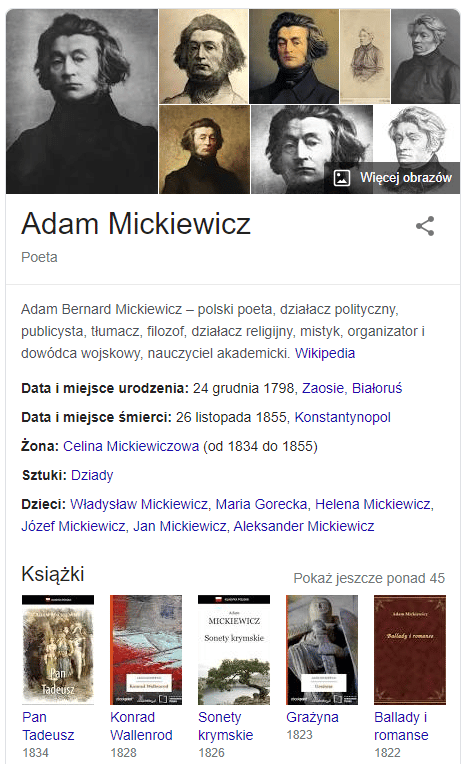
Skrócony przykład dla strony o Adamie Mickiewiczu:
Jak widzisz na powyższym przykładzie, Google otrzymuje od nas aż 3 dodatkowe argumenty, by jasno zrozumieć o czym jest nasza strona. Oprócz samej treści strony oraz danych strukturalnych, dzięki sameAs Google wie, że piszemy o:
Adamie Mickiewiczu, którego opisuje artykuł na Wikipedii,
Adamie Mickiewiczu, który znalazł się w bazie Wikidata,
Adamie Mickiewiczu, którego samo Google opisuje w swoim knowledge graphie.
Skąd ta idea? Freebase a Google
Freebase było bodaj pierwszą otwartą bazą, która nadawała jednostkom danych unikalne ID. Google nabyło tę bazę w 2010 roku, a w 2016 zamknęło ją, ogłaszając Knowledge Graph API oficjalnym następcą. Dane z Freebase krążą w postaci dumpów w sieci oraz zostały zmigrowane do serwisu Wikidata.
Freebase było przez pewien czas głównym źródłem danych dla Knowledge Graphów Google.
Dane pozyskane w czasie istnienia Freebase oznaczone są ID rozpoczynającym się od /m/… Dane zebrane później przez Google mają ID w formacie /g/…
Jakie to ma znaczenie dla SEO?
Teoretycznie? Olbrzymie. Praktycznie? Wciąż niewielkie, ale na pewno nie do zignorowania.
Wiedza o istnieniu czegoś takiego jak Entity ID w Google jest cenna, ale to fundament pod planowanie, budowanie strategii, a nie gotowe, jednolinijkowe rozwiązanie, które wysadzi wyniki Twojej strony w kosmos.
MREID ostatecznie udowadnia, że czas zapomnieć o keywordach
Istnienie unikalnych ID nazywających niemal wszystkie zakresy wiedzy w internecie to ulga dla mojej duszy. Ulga, bo być może niektórzy specjaliści skończą w końcu swoje durne wywody o słowach kluczowych.
MREID to ostateczny dowód, że finalnie przyszedł czas by pożegnać się z rozumieniem pozycjonowania, jako windowania pojedynczych słów w wynikach Google. Entity IDs nie nazywają przecież pojedynczych słów, one nazywają rzeczy, zjawiska, ludzi.
To pokazuje jak Google rozumie świat. Na swój maszynowy sposób rozumie go doskonale.
„Adam Mickiewicz” nie jest dla niego więc dwuwyrazowym zbitkiem 14 liter, ale: człowiekiem, mężczyzną o drugim imieniu Bernard, urodzonym, ochrzczonym, wykształconym, mieszkającym i zmarłym w konkretnym czasie i miejscu, pochowanym w miejscu o konkretnych współrzędnych geograficznych, mający znanego z imienia ojca, matkę, dzieci, rodzeństwo, żonę, kochanki, posługującego się konkretnymi językami, reprezentującym romantyzm, twórcą konkretnych dzieł i będący konkretnego wyznania.
To wiedza daleko wykraczająca poza słowo kluczowe „Adam Mickiewicz”.
Smutne jest to, że ten „ostateczny dowód” istnieje w powszechnym użyciu od ok. 10 lat, a wciąż semantyczne SEO jest tematem, z grubsza mówiąc, ignorowanym.
Budowanie własnej marki
Warto znać swoje ID w Google, niezależnie czy promujemy swój produkt, swoją firmę, czy samego siebie.
Czy trzeba być dużym podmiotem, by Google raczyło przydzielić nam unikalne ID? I tak i nie. Jeśli Twoja firma czy brand ma swoją stronę na Wikipedii, to możesz spać spokojnie. Prawdopodobnie Google już Cię oznaczyło 😉
Nie oznacza to, że swoje ID mają tylko ludzie sławni i wielkie korporacje. Czasem wydaje się, że samo posiadanie konta Google Moja Firma załatwia sprawę, choć nie zawsze się to sprawdza. Znam sporo agencji SEO, które mają swoje MREID, choć prawdopodobnie nawet o tym nie wiedzą.
Ma to swoje pozytywne konsekwencje, jak np. pojawianie się w podpowiedziach przy wpisywaniu haseł, np. w Google Trends. Nie jest to kwestia dogłębnie zbadana, ale prawdopodobnie posiadanie takiego Entity ID wiąże się z odpowiednią reputacją w oczach Google.
Wątpliwości co do treści
Odwoływanie się do MREID i knowledge graphu może wyjaśnić wszelkie wątpliwości, jakie Google ma co do naszej treści. Podany wyżej przykład z aktorką Anne Hathaway oraz żoną Szekspira – Anne Hathaway – to wersja jaskrawa tego problemu.
Na codzień sameAs i MREID może pomóc w mniej oczywistych, ale równie problematycznych treściach. Algorytm to tylko maszyna – podanie jej na tacy jak największej ilości precyzyjnych danych zwiększa szansę na obopólne porozumienie z webmasterem.
SEOwcy mogą więc w przyszłości traktować sameAs i oznaczenie w nim MREID jako pewne rozwinięcie idei linków kanonicznych.
Wyobraźmy sobie taką sytuację:
mamy artykuł na temat A
mamy artykuł na temat B, który w jednym akapicie wspomina o temacie A.
Niestety, okazuje się, że na frazy związane z tematem A rankuje nam strona z tematem B.
oznaczamy więc stronę A stosownym MREID dla tematu A
oznaczamy stronę B stosownym MREID dla tematu B
Teoretycznie rozwiązanie takie powinno pomóc Google’owi zrozumieć, o czym opowiadają poszczególne strony.
Teoretycznie, bo oczywiście wiele tematów semantycznego SEO, które tu prezentuję to kwestia najbliższej przyszłości. Konkretne rozwiązania mogą jeszcze nie przynosić efektów, ale samo istnienie elementów takich jak MREIDs to fakt, który już teraz powinien być podstawą niektórych strategii SEO.
Google nadaje ID wszystkiemu co ma znaczenie, nazwijmy to, „globalne”. Jeśli aplikacja / strona / PWA jest popularna na tyle, że staje się odrębną jednostką w świadomości większej grupy ludzi, to prędzej czy później Google nada jej swoje ID.








Artykuł wysokie klasy. Czy jest możliwe stworzenie MREID dla aplikacji pwa ?
Google nadaje ID wszystkiemu co ma znaczenie, nazwijmy to, „globalne”. Jeśli aplikacja / strona / PWA jest popularna na tyle, że staje się odrębną jednostką w świadomości większej grupy ludzi, to prędzej czy później Google nada jej swoje ID.