MREID (Machine-Readable Entity IDs), or how Google understands the world
20 Apr
I don’t know if this will surprise you or not, but Google has given almost every element of the known world a unique ID. Today, a little bit about those unique numbers, which – not knowing why – are not talked about much in the SEO world.
Almost every major company, celebrity, animal, plant, invention, phenomenon, film, artistic work, event, organization, ideology…. almost anything you can read about on the Internet has a number. Ba, it even has dozens of numbers and designations given by various bodies and organizations, but we are necessarily interested in the designation Google uses.
Do you know the actress, Anne Hathaway?
photo. left: ONU Brasil
That’s her on the left. On the right is probably the only surviving drawing of another Anne Hathaway, Shakespeare’s wife.
Since both ladies have the exact same name, how is Google supposed to know which one we just wrote an article about? We could, of course, supplement the structured data and, for example, elaborate on the films the actress appeared in, the awards she received, etc. But wouldn’t it be simpler to associate our article with the knowledge Google already has about these ladies?
Spis treści
MREID a Google
This is where something conventionally called MREID, or Machine-Readable Entity ID, enters the scene. In Google’s API documentation, this is simply the ID or KGID (Knowledge Graph ID).
This is a unique ID given to units of information and used in many products across the Google ecosystem – Search, Image Search, Google Trends and many others.
Anne Hathaway, who is an actress, is thus /m/02vntj in the eyes of Google, while Shakespeare’s wife is known by the pseudonym /m/03mzbg. Isn’t that adorable?
ID of this type is given in so many areas that it is difficult to be tempted to list. All works, books, movies, famous people, teams, events, well-known organizations, big companies, publishing houses, sports teams, video games, series, historical events, parties…. all these units of knowledge have their own unique ID.
How do we find the MREID we are interested in?
The ways to do this are many.
Wikidata
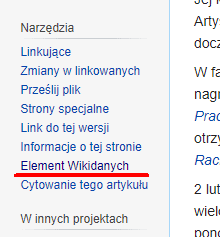
The simplest, yet incomplete, is the Wikidata service. You can search for items of interest directly on the site, or, if you find it more convenient, click the relevant link next to each Wikipedia article.
You can find the ID you are interested in under Freebase ID:
By the way – recently on one of the Facebook SEO groups I came across a question about a tool that for a list of keywords will select categories, related topics, etc. Innate shyness and laziness caused me not to respond, but Wikidata and a little XPath-a is the answer to this problem 😉
Google Trends
A very simple way is also to use Google Trends. Just type in the keyword you are interested in and wait for a hint from Google:
Once clicked, MREID will appear to us in the URL:
Of course, the address bar shows us the percentage-encoded version: %2F is obviously a slash /.
{
"@context": {
"@vocab": "http://schema.org/",
"goog": "http://schema.googleapis.com/",
"resultScore": "goog:resultScore",
"detailedDescription": "goog:detailedDescription",
"EntitySearchResult": "goog:EntitySearchResult",
"kg": "http://g.co/kg"
},
"@type": "ItemList",
"itemListElement": [
{
"@type": "EntitySearchResult",
"result": {
"@id": "kg:/m/0dl567",
"name": "Taylor Swift",
"@type": [
"Thing",
"Person"
],
"description": "Singer-songwriter",
"image": {
"contentUrl": "https://t1.gstatic.com/images?q=tbn:ANd9GcQmVDAhjhWnN2OWys2ZMO3PGAhupp5tN2LwF_BJmiHgi19hf8Ku",
"url": "https://en.wikipedia.org/wiki/Taylor_Swift",
"license": "http://creativecommons.org/licenses/by-sa/2.0"
},
"detailedDescription": {
"articleBody": "Taylor Alison Swift is an American singer-songwriter and actress. Raised in Wyomissing, Pennsylvania, she moved to Nashville, Tennessee, at the age of 14 to pursue a career in country music. ",
"url": "http://en.wikipedia.org/wiki/Taylor_Swift",
"license": "https://en.wikipedia.org/wiki/Wikipedia:Text_of_Creative_Commons_Attribution-ShareAlike_3.0_Unported_License"
},
"url": "http://taylorswift.com/"
},
"resultScore": 4850
}
]
}
SERP code
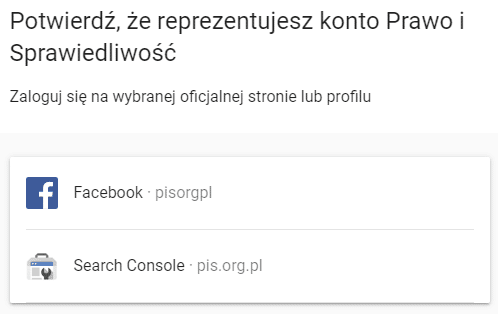
You can also learn about MREID by looking at the SERP’s source code, which displays a knowledge graph with the topic of interest.
The MREID in the code is displayed several times, but it is easiest to find it if the “Report the right to this knowledge panel” button is displayed under the knowledge grapheme.
The link of this button leads to the page:
https://posts.google.com/claim/?mid=/m/02vntj
… Which gives us the finished MREID.
By the way, it’s worth clicking that button out of sheer curiosity. For example, you can find out who bothered to set up Google Search Console for themselves 🙂
Other
MREIDs can be reached in several other ways, but I think I have presented enough methods. Others include digging further into the code of Google’s pages, creating yourself a JS script that displays the MREID in the console, or, for example, using Freebase dump pages like this one.
How do you link your content to Google’s database?
This property is very rarely flagged by webmasters, and if it is, it is limited to pointing to the relevant page on Wikipedia.
Meanwhile, nothing prevents structured data in JSON-LD format from containing arrays; indicating more than one sameAs property is therefore not a problem.
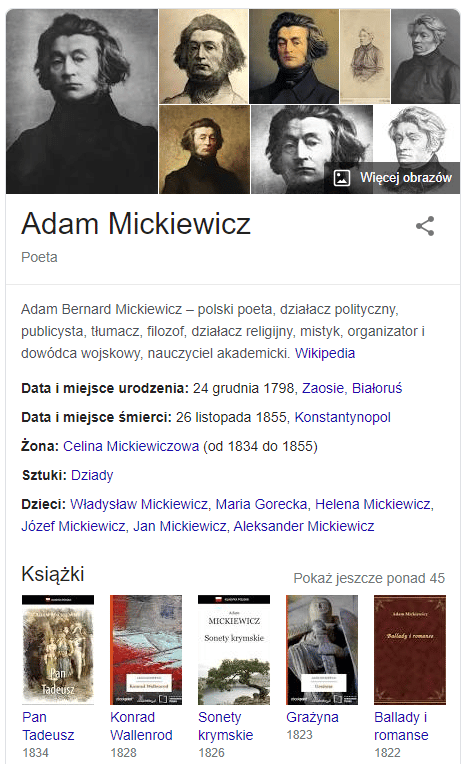
An abbreviated example for a page on Adam Mickiewicz:
As you can see from the example above, Google gets as many as 3 additional arguments from us to clearly understand what our site is about. In addition to the page content itself and the structural data, thanks to the sameAs Google knows that we write about:
Adam Mickiewicz, whom the Wikipedia article describes,
Adam Mickiewicz, which was included in the Wikidata database,
Adam Mickiewicz, whom Google itself describes in its knowledge graph.
Where did the idea come from? Freebase vs Google
Freebase was perhaps the first open database to give data units unique IDs. Google acquired the database in 2010 and closed it in 2016, announcing Knowledge Graph API as its official successor. Data from Freebase circulates as dumps on the web and has been migrated to Wikidata.
Freebase was for some time the main source of data for Google’s Knowledge Graphs.
Data acquired during the existence of Freebase is marked with an ID starting with /m/.… Data collected later by Google has an ID in the format /g/….
How important is this for SEO?
Theoretically? Huge. Practically? Still small, but certainly not to be ignored.
Knowing that there is such a thing as Entity ID in Google is valuable, but it’s a foundation for planning, building a strategy, not a ready-made, one-line solution that will blow your site’s results into space.
MREID finally proves it’s time to forget about keywords
The existence of unique IDs naming almost all scopes of knowledge on the Internet is a relief to my soul. It’s a relief, because perhaps some specialists will finally end their foolish arguments about keywords.
MREID is the ultimate proof that the time has finally come to say goodbye to the understanding of SEO as elevating single words in Google results. Entity IDs, after all, do not name individual words, they name things, phenomena, people.
This shows how Google understands the world. In her machine-like way, she understands him perfectly.
“Adam Mickiewicz” is therefore for him not a two-word cluster of 14 letters, but a: a man, a man with the middle name Bernard, born, baptized, educated, lived and died in a specific time and place, buried in a place with specific geographical coordinates, having a father, mother, children, siblings, wife, lovers known by name, speaking specific languages, representing Romanticism, creator of specific works and being of a specific religion.
This knowledge goes far beyond the keyword “Adam Mickiewicz.”
The sad thing is that this “definitive proof” has been in common use for ca. 10 years, and still semantic SEO is a topic, roughly speaking, ignored.
Building your own brand
It’s worth knowing your ID on Google, whether you’re promoting your product, your company, or yourself.
Do you have to be a large entity for Google to deign to assign us a unique ID? And yes and no. If your company or brand has a page on Wikipedia, you can rest easy. Probably Google has already tagged you 😉
This does not mean that only famous people and large corporations have their IDs. Sometimes it seems that just having a Google My Business account gets the job done, though that doesn’t always work. I know quite a few SEO agencies that have their MREID, although they probably don’t even know it.
This has its own positive consequences, such as appearing in keyword suggestions, such as in Google Trends. This is not a deeply researched issue, but it is likely that having such an Entity ID comes with a corresponding reputation in the eyes of Google.
Doubts about the content
Referring to MREID and knowledge graph can clear up any doubts Google has about our content. The example given above with actress Anne Hathaway and Shakespeare’s wife Anne Hathaway is a glaring version of this problem.
On a daily basis, sameAs and MREID can help with less obvious but equally problematic content. An algorithm is just a machine – giving it as much precise data as possible on a platter increases the chance of mutual agreement with the webmaster.
Thus, SEOs may in the future treat sameAs and the MREID designation therein as some development of the idea of canonical links.
Imagine such a situation:
we have an article on A
we have an article on topic B that mentions topic A in one paragraph.
Unfortunately, it turns out that for phrases related to topic A, we are ranked by a site with topic B.
So we mark page A with the appropriate MREID for subject A
we mark page B with the appropriate MREID for subject B
In theory, such a solution should help Google understand what each page is about.
Theoretically, because of course, many of the semantic SEO topics I present here are a matter of the near future. Specific solutions may not yet bear fruit, but the very existence of elements such as MREIDs is a fact that should already be the basis of some SEO strategies.