

Długo mnie tu nie było, bo zajęty byłem, o dziwo, robieniem SEO. Przerywam ten pracoholiczny trans przeplatany internetowymi gównoburzami z linkbuilderskim betonem po to, by wrócić i zająć się nieco dokładniej tematyką entities w SEO.
Rok temu pisałem dość dużo o MREID – czyli o tym, że wszystko w oczach Google ma swój numerek. Łącznie z chorobami, wydarzeniami historycznymi, osobami, markami itp. itd.
Artykuł ten, choć skupiał się na samym MREID (które w międzyczasie w dokumentacji ugruntowało się już pod zwięźlejszym skrótem mid) tak naprawdę mówi przecież o samych entities – ID nadawane przez Google są tylko kodem wywoławczym entities.
Czym więc jest w SEO pojęcie entity?
Jak tłumaczyć słowo entity?
Entity to po angielsku po prostu jednostka, podmiot. Nie ma chyba lepszego tłumaczenia dla tego słowa niż te dosłowne.
Jeszcze precyzyjniej brzmi: jednostka wiedzy.
Choć o temacie entities mówi się jeszcze zadzwiająco mało, spotkałem się już z tłumaczeniem entities jako encje.
Choć w niektórych dziedzinach informatyki używa się tego tłumaczenia właśnie dla pewnych jednostek wiedzy, to jednak ma ono również zastosowanie np. w kodowaniu znaków (encje HTML) i może to się trochę mieszać.
Cóż, z czasem użytkownicy języka sami wybiorą sobie najdogodniejszą formę.
Spis treści
Czym w SEO są Entities?
Jednostki wiedzy to faktycznie najlepsze określenie na entities zarówno pod względem semantycznym jak i merytorycznym. Są to bowiem takie ustrukturyzowane zakresy wiedzy, które opisują jeden element.
Może to być:
- osoba
- drużyna piłkarska
- zjawisko pogodowe
- teoria naukowa
- wydarzenie historyczne
- firma
- produkt
- film
- kolor
- planeta
- data
- prawo fizyki
- pierwiastek chemiczny
- choroba
- itd.
Jak widzimy jednostką wiedzy może być wszystko, co da się opisać w sposób ustrukturyzowany, np.
Nazwa: FC Barcelona Rodzaj: drużyna piłkarska; profesjonalna drużyna sportowa; klub sportowy Data powstania: 29-11-1899 Pełna nazwa: Futbol Club Barcelona Kraj: Hiszpania Stadion: Camp Nou Sport: piłka nożna
Google zapisuje każdą jednostkę wiedzy za pomocą różnych typów danych:
- nazwa
- ID (w artykule sprzed roku piszę o MREID, w API pojawia się mid – zwał jak zwał)
- klasa – krótko mówiąc: czym jest dany obiekt, np. film
- atrybut – np. liczba minut trwania filmu, data premiery
- relacja – sposób w jaki obiekt powiązany jest z inną jednostką wiedzy (np. Pulp Fiction i Quentin Tarantino powiązani są relacją Director (reżyseria)
- relevance – ocena trafności danego powiązania, np. czarny to na 0.99 kolor, ale czy Pulp Fiction to na pewno komedia?
Co ważne, w większości wypadków jednostki wiedzy opisywane są za pomocą innych jednostek wiedzy, np. enitity Pulp Fiction jako reżysera zapisaną ma entity Quentin Tarantino.
Choć to prosta definicja, takie podejście do gromadzenia informacji, oparte na ustrukturyzowanych danych, a nie zwykłych ciągach znaków, rodzi niesamowite wręcz konsekwencje.
Dlaczego entity oriented search rewolucjonizuje wyszukiwanie informacji?
Na początku było słowo. Google w swojej oldschoolowej wersji miało do dyspozycji tekst. Wynajdywane na milionach różnych stron internetowych teksty roboty, niczym średniowieczni mnisi, zapamiętywały, przepisywały i kopiowały.
Owi mnisi, czyli nasze roboty i serwery Google nie potrafili spamiętać wszystkich przepisanych i skopiowanych ksiąg. Tekst tkwił więc na półkach w wielkich bibliotekach.
Kiedy użytkownik wykonywał wyszukiwanie, np. szukał informacji o ćwierćcalowej treblince do kombajnu, żaden z mnichów nie potrafił mu odpowiedzieć, bo mnisi nie znają się na ćwierćalowych treblinkach do kombajnu. Mnisi potrafili tylko znaleźć w bibliotece książkę o kombajnach, książkę o treblinkach i w obu tych księgach poszukać czegoś o elementach ćwierćalowych.
Rozwój wyszukiwarki polegał tylko na tym, że mnisi wyszukiwali informacje coraz szybciej, coraz mądrzej je katalogowali, coraz lepiej oceniali jakość ksiąg w których mają szukać informacji, coraz mądrzej układali je na półkach, tak by łatwiej było je później odnaleźć. Tylko tyle i aż tyle.
I tutaj analogia do średniowiecznych skrybów się kończy, bo nagle nastąpiła pewna rewolucja. Entity Oriented Search i w ogóle sama idea gromadzenia informacji nie jako zbioru tekstów, ale klastry uporządkowanej wiedzy, zmieniła wyszukiwanie bezpowrotnie. Sprawiła, że baza danych Google to teraz księga zawierająca wszystkie dane, samowystarczalna, w przypisach jedynie odwołująca się do innych ksiąg. Ale to nie wszystko.
W 2010 roku Google nabyło bazę danych Freebase, a teraz wciąż rozwija ją w Knowledge Graphach, część z niej udostępniając nawet przez API. Dzięki temu mamy wgląd w to co Google już wie. A wie mnóstwo i to widać także na codzień w SERPie:
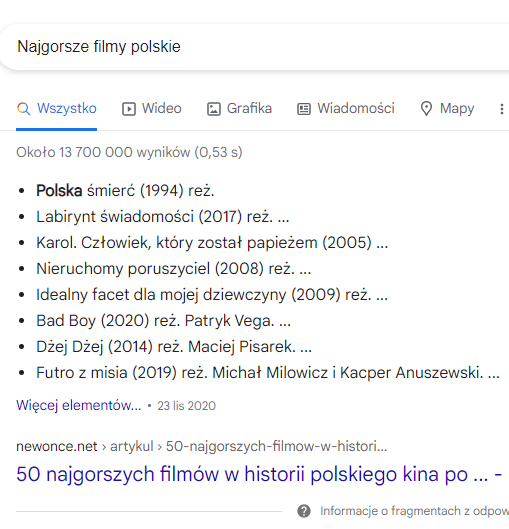
Powyżej widzimy przykład starego podejścia do wyszukiwania informacji. Google, biorąc pod uwagę wiele czynników rankingowych, ocenił, że ten właśnie artykuł będzie najbardziej stosowny. W porządku, nie omawiamy teraz jakości wyników, tylko sposób ich wyboru i prezentacji.
Wybór Google padł właśnie na ten artykuł z wielu powodów, ale większość z nich oparta jest na przesłankach wynikających z ciągu tekstowego. Google nie zaprezentował nam na tym przykładzie, że rozumie to zagadnienie, nie wiemy nawet że wie, iż chodzi o filmy. Być może wie, może nie, trudno powiedzieć.
Co więcej, podkreślił słowo Polska, co świadczy, że po prostu ten wynik wydał mu się istotny, mimo że dla naszego zapytania nie ma to żadnego sensu.
A teraz dla kontrastu:
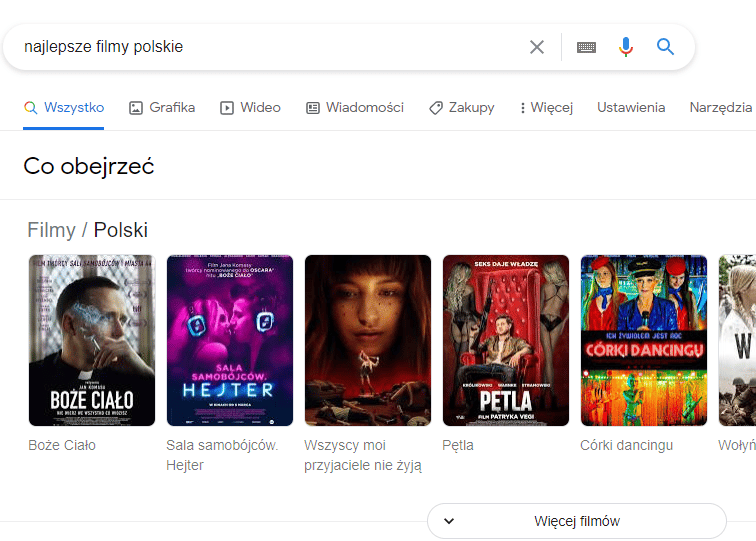
Tutaj już snippet oparty jest na konkretnych jednostkach wiedzy. Google nie proponuje jako odpowiedzi na zapytanie ciągu znaków, lecz konkretne propozycje filmowe.
Wybrał je, bo jednostka wiedzy zawiera informację, że film jest polski i że ma najlepsze recenzje.
Oczywiście po ich kliknięciu mamy kompleksową informację o każdym z filmów:
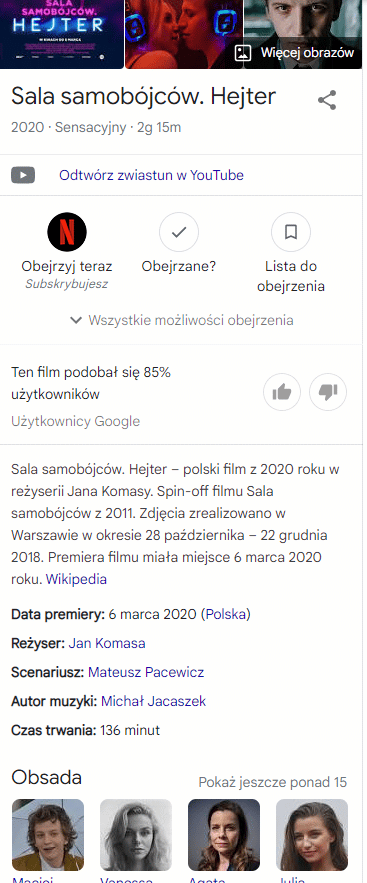
Z tego tylko jednego przykładu wysnuwają się nam cztery absolutnie najważniejsze wnioski z wpływu entities na wyszukiwanie:
Po pierwsze: to podejście wymusza szukanie innej drogi by uniknąć zero click searches
Dziś na tym się nie chcę skupiać, ale wniosek jest prosty: możesz wydać wielocyfrowe budżety na Whitepressie, ale i tak Top 1 dla tego typu fraz może być ryzykowną inwestycją za sprawą zero click searches. Spójrzmy prawdzie w oczy: dla wielu branż czas stworzyć strategię pojawienia się tu gdzie na grafice powyżej widzimy Netflix, zamiast wydawać bajońskie sumy celując w top 10. Można zaklinać rzeczywistość, ale nie można tego robić w nieskończoność. Amen.
Po drugie: zmienia się sposób prezentacji danych
Wniosek trywialny i oczywisty, ale czy oczywiste są konsekwencje jakie to za sobą niesie? A te są dość obszerne, bo na przykład:
- kompletna zmiana sposobu wyszukiwania informacji w oczekiwaniu na inny niż dotąd wynik wyszukania (pa pa, długie ogony),
- zmiana sposobu konsumpcji informacji z obszerniejszych form tekstowych na suche fakty i podsumowania w formie krótkich snippetów,
- kompletne zredefiniowanie samego charakteru procesu wyszukiwania.
Poprzez to ostatnie mam na myśli zmianę z modelu inbound na coś znacznie bardziej rozszerzonego. Oto bowiem użytkownik szukający informacji o filmie otrzymuje od razu zdjęcie reżysera i całej obsady, zaproszenie do obejrzenia filmu, do obejrzenia zwiastunu, do dalszego wyszukiwania informacji powiązanych itd.
Rozszerza się więc klasyczny dla wyszukiwarek model inbound marketingu, w którym to użytkownik przychodzi i wywołuje treści na własne życzenie – teraz to treści przychodzą do użytkownika, który ledwie zdąży wyrazić nimi zainteresowanie. To już nie jest tylko mały boks People Also Ask.
Po trzecie: siła jednostek wiedzy tkwi przede wszystkim w relacjach między nimi
Czym byłyby entities, gdyby Google nie rozumiał jak są one ze sobą powiązane? Chyba właśnie w relacjach między nimi tkwi cała siła tej idei.
Wyobraźmy sobie taki zbiór jednostek wiedzy:
Nazwa: Adam Mickiewicz Zawód: pisarz Kraj: Polska Miejsce urodzenia: Nowogródek Miejsce śmierci: Konstantynopol Wykształcenie: Uniwersytet Wileński Nazwa: Józef Ignacy Kraszewski Zawód: pisarz Kraj: Polska Miejsce urodzenia: Warszawa Miejsce śmierci: Genewa Wykształcenie: Uniwersytet Wileński
Gdyby Google nie rozumiało relacji pomiędzy tymi jednostkami wiedzy, możliwe byłoby uzyskanie tylko prostych informacji, np.:
Zapytanie: polski pisarz urodzony w Nowogródku Odpowiedź: Adam Mickiewicz
albo
Zapytanie: sławni absolwenci uniwersytetu wileńskiego Odpowiedź: Adam Mickiewicz;Józef Ignacy Kraszewski
Jednak dopiero dzięki rozumieniu relacji pomiędzy jednostkami wiedzy, i dalszemu ich analizowaniu, jesteśmy w stanie wykonać takie zapytanie:
Zapytanie: sławni Polscy pisarze zmarli poza Polską Odpowiedź: Adam Mickiewicz;Józef Ignacy Kraszewski
Kluczem decydującym o powodzeniu takiego zapytania, jest fakt, że dane o każdej jednostce są nie tylko ustrukturyzowane, ale też powiązane.
To, że nasze przykładowe postacie są Polakami, pisarzami, oraz że skończyli Uniwersytet Warszawski wynika bezpośrednio z danych.
To, że zmarli poza Polską wynika z faktu, że we fragmencie:
Miejsce śmierci: Genewa
…Genewa nie jest zwykłym ciągiem znaków, ale odrębną jednostką wiedzy.
Google nie tylko więc wie, że Kraszewski zmarł w Genewie. Google wie, że Kraszewski zmarł w Genewie, która jest miastem w Szwajcarii (a nie w Polsce), 200 000 ludności, stolica kantonu Genewa, oficjalny język francuski itd.. Że Mickiewicz zmarł w Konstantynopolu, który jest historyczną nazwą Stambułu i że ten leży w Turcji.
To zupełnie zmienia postać rzeczy; zrozumienie relacji między poszczególnymi entities otwiera kolejne nieprzebrane pokłady wiedzy i dostępu do danych.
Po czwarte: nie jest oczywiste co jest, a co nie jest czynnikiem rankingowym
Załóżmy, że uda nam się jakoś uszczknąć z tego tortu.
Posługując się dalej przykładem branży filmowej, uda nam się wskoczyć do knowledge graphu ze swoją stroną jako nieodłączny element wiedzy o danym filmie.
Co teraz? Ano jakoś trzeba zadbać, by – skoro już tam jesteśmy – pojawiać się jak najczęściej. Czy da się pozycjonować jednostki wiedzy?
Teoretycznie tak, szczególnie w niszach, gdzie sygnałów i źródeł do kolekcjonowania wiedzy Google ma mniej – łatwiej więc je zmanipulować.
Jak to zrobić – to zapewne już Wam za parę lat opiszą wszelkiej masy specjaliści, jak się przebudzą: content, dane strukturalne i Bóg wie co jeszcze.
A ja chciałbym tylko zwrócić uwagę na pewien problem.
Jeśli SEO za kilkanaście lat będzie polegało na „wskakiwaniu” w knowledge graphy i promowaniu ich*, wtedy to coś co dziś znamy pod pojęciem sygnału rankingowego straci na znaczeniu.
Bo jakież znaczenie będą miały nasze starania, jeśli dla frazy:

… największe znaczenie będzie miało to:
… i tego raczej nie przeskoczymy.
Mówiąc prościej: dziś, na pytanie o to, czy najbliższa niedziela jest handlowa niektórzy spece potrafią co tydzień pisać nową rozprawkę. Jednak wkrótce na pytanie czy 2 + 2 równa się 4 będzie możliwa tylko jedna odpowiedź.
Suche fakty będą miały przewagę nad pozycjonerskim kombinowaniem. Świetne wieści dla użytkowników, dla nas trochę gorsze 🙂
* To w sumie niegłupia idea. Czy na tym może polegać SEO przyszłości, że dla każdego produktu, rzeczy czy promowanej usługi powstanie coś na wzór knowledge grapha i trzeba go będzie tylko dopieszczać i ewentualnie uzupełniać dane? Brzmi to całkiem realnie, ale to oczywiście tylko wróżenie z fusów.
Jak Google poradziło sobie z największym problemem z Entity Oriented Search
Na początku wprowadziłem analogię pierwotnej technologii Google, porównując boty do średniowiecznych mnichów, spisujących i porządkujących teksty w księgach.
Obecnie Google to taki supermózg, który najważniejszą wiedzę z tych ksiąg już sobie przyswoił i ma do niej błyskawiczny dostęp.
Problemy pozostały dwa.
Pierwszy jest taki, że wciąż bardzo, bardzo dużo z tej wiedzy pozostaje zapisane tylko w księgach. Dzieje się tak dlatego, że Google łatwo przyswoił wiedzę która była usystematyzowana, w jakiś sposób uporządkowana. Pozostała olbrzymia ilość wiedzy nabazgranej w rękopisach, dziwnych językach, nieczytelna.
Mamy więc w bazie danych pewne rozdwojenie – z jednej strony Google dysponuje supernowoczesną bazą entities, którą potrafi przerabiać, łączyć i dostosowywać do zapytania, a z drugiej – olbrzymi, nieuporządkowany zbiór tekstów, w których wyszukuje z większą lub mniejszą skutecznością odpowiedzi na pytania zadawane przez użytkowników. I podejrzewam, że ów drugi rodzaj zbioru danych, jest w większości języków (w tym polskim) znacznie większy objętościowo niż ten pierwszy.
I nawet nie to jest najważniejszym problemem – takie współistnienie tych różnych rodzajów danych trwa już długi czas i świat się nie zawalił.
Najważniejszym problemem Google jest połączenie tych zasobów w całość. Zmapowanie wiedzy ustrukturyzowanej z nieustrukturyzowaną. I to się właśnie dzieje: na naszych oczach coraz więcej fraz i zapytań będzie otrzymywało swoje knowledge graphy, rozbudowane snippety, czy po prostu błyskawiczne odpowiedzi oparte na danych.
Na pytanie jak Google to robi odpowiedź jest oczywiście tylko jedna: sztuczna inteligencja. Jednak takie banalne odpowiedzi nikogo nie zadowalają, dlatego postanowiłem przyjrzeć się temu zagadnieniu dokładniej.
Co nam podpowiada Cloud Natural Language API
Gdzie szukasz informacji o tym nad czym Google pracuje i co będzie trendem w SEO w najbliższych latach?
- oświadczenia prasowe Google i ich blogi?
- dokumentacja promowanych projektów (np. AMP)?
- blogi branżowe?
- własna intuicja?
- patenty Google?
Wszystko to bardzo dobre drogi, szczególnie jeśli odsieje się działania stricte PR-owe a najwięcej czasu spędzi na studiowaniu patentów.
Jest jednak jeszcze jedna wskazówka, którą często się pomija, a mianowicie API i ich dokumentacja.
Dla naszego tematu najbardziej stosowne byłoby zajęcie się Knowledge Graph Search API, dzięki któremu możemy wyszukać dane o niektórych jednostkach wiedzy.
Gorąco polecam zabawę tym cudeńkiem, ale ja dzisiaj nie o tym.
Skupmy się na Cloud Natural Language API. Jest to usługa pozwalająca na użycie sztucznej inteligencji do zrozumienia treści na podstawie samego tylko czystego tekstu.
Oto jak dużo Google już potrafi. Na samym tylko czystym tekście API może wykonać:
- Sentiment analysis – ocena głównej emocji towarzyszącej tekstowi, skupiająca się na biegunach: pozytywny, neutralny, negatywny.
- Entity analysis – „wyciąga” i rozpoznaje z tekstu wszystkie rozpoznane entities
- Entity sentiment analysis – wyciąga z tekstu wszystkie rozpoznane entities i zwraca info o emocjach w jakich są one przywoływane (pozytywne, neutralne, negatywne)
- Syntactic analysis – dzieli tekst na zdania i/lub tokenizuje, a następnie zwraca informacje o kontekście dla zdań/tokenów
- Content classification – nadaje treści kategorię.
Oto więc mamy narzędzie, które z prostego tekstu wyodrębnia jednostki wiedzy. Na przykład zdanie:
President Trump will speak from the White House, located at 1600 Pennsylvania Ave NW, Washington, DC, on October 7.
… zwraca:
{
"entities": [
{
"name": "Trump",
"type": "PERSON",
"metadata": {
"mid": "/m/0cqt90",
"wikipedia_url": "https://en.wikipedia.org/wiki/Donald_Trump"
},
"salience": 0.7936003,
"mentions": [
{
"text": {
"content": "Trump",
"beginOffset": 10
},
"type": "PROPER"
},
{
"text": {
"content": "President",
"beginOffset": 0
},
"type": "COMMON"
}
]
},
{
"name": "White House",
"type": "LOCATION",
"metadata": {
"mid": "/m/081sq",
"wikipedia_url": "https://en.wikipedia.org/wiki/White_House"
},
"salience": 0.09172433,
"mentions": [
{
"text": {
"content": "White House",
"beginOffset": 36
},
"type": "PROPER"
}
]
},
{
"name": "Pennsylvania Ave NW",
"type": "LOCATION",
"metadata": {
"mid": "/g/1tgb87cq"
},
"salience": 0.085507184,
"mentions": [
{
"text": {
"content": "Pennsylvania Ave NW",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
{
"name": "Washington, DC",
"type": "LOCATION",
"metadata": {
"mid": "/m/0rh6k",
"wikipedia_url": "https://en.wikipedia.org/wiki/Washington,_D.C."
},
"salience": 0.029168168,
"mentions": [
{
"text": {
"content": "Washington, DC",
"beginOffset": 86
},
"type": "PROPER"
}
]
}
{
"name": "1600 Pennsylvania Ave NW, Washington, DC",
"type": "ADDRESS",
"metadata": {
"country": "US",
"sublocality": "Fort Lesley J. McNair",
"locality": "Washington",
"street_name": "Pennsylvania Avenue Northwest",
"broad_region": "District of Columbia",
"narrow_region": "District of Columbia",
"street_number": "1600"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "1600 Pennsylvania Ave NW, Washington, DC",
"beginOffset": 60
},
"type": "TYPE_UNKNOWN"
}
]
}
}
{
"name": "1600",
"type": "NUMBER",
"metadata": {
"value": "1600"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "1600",
"beginOffset": 60
},
"type": "TYPE_UNKNOWN"
}
]
},
{
"name": "October 7",
"type": "DATE",
"metadata": {
"day": "7",
"month": "10"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "October 7",
"beginOffset": 105
},
"type": "TYPE_UNKNOWN"
}
]
}
{
"name": "7",
"type": "NUMBER",
"metadata": {
"value": "7"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "7",
"beginOffset": 113
},
"type": "TYPE_UNKNOWN"
}
]
}
],
"language": "en"
}
Co tu się odtrumpiło? Na podstawie jednego zdania za pomocą API ustaliliśmy język, określiliśmy kogo dotyczy tekst, jaką funkcję ten ktoś pełni, gdzie będzie, jak nazywa się to miejsce i jaki jest jego dokładny adres.
I nie są to dane oderwane od rzeczywistości. Możemy je za pomocą ID dalej przyporządkowywać i łączyć różne teksty w jeden blok znaczeniowy.
Ba, mało tego. Gdybyśmy na początku zdania dodali np. „Our beloved master President Trump…” i zamiast metody analyzeEntities użyli metody analyzeEntitySentiment to dodatkowo jeszcze Google oceniłoby nasz stosunek do Trumpa (a przy okazji neutralny stosunek do Pennsylvania Avenue, Białego Domu i do daty 7 października 😉 ).
Google potrafi już tak wiele, a pamiętajmy, że to jest technologia udostępniana publicznie. Co dzieje się „pod maską” i jakie nowe zdolności do kategoryzowania i lepszego rozumienia tekstu są już testowane – tego nie wiemy.
Kwestią czasu jest więc usystematyzowanie całej wiedzy do jakiej dostęp ma Google – a z biegiem czasu ten proces może tylko przyspieszyć.
No dobra, ale co dalej?
Ano nic. Jest to rewolucja, która toczy się powoli, ale trwa już dość długo. Zadziało się w temacie na tyle dużo, że postanowiłem zebrać to do kupy i omówić skupiając się na powodach, a nie objawach.
A jakie są to objawy, to już chyba nie trzeba nikomu tłumaczyć: 65% wyszukań nie zakończonych kliknięciem w 2020 roku. Mógłbym tu wkleić screeny na których widać wpływ koncentracji Google na entities na taki stan rzeczy, ale skoro dobrnęłaś/dobrnąłeś do tej części artykułu, to zapewne doskonale zdajesz sobie z tego sprawę.
Choć Entity Oriented Search stawia na głowie wszystkie dotychczasowe dogmaty SEO, specjaliści z pewnością będą próbowali dobrać się do jednostek wiedzy tak, by w jakiś sposób ich klienci byli ich częścią (ja już próbuję, ale bez technik spod ciemnego kapelusza nie jest to proste 😉 ). Konserwatyści będą sprawę olewać do ostatniej chwili. A ja myślę, że róbmy swoje, ale w tyle głowy miejmy jakiś plan, jakąś strategię, która w końcu pozwoli nam się włamać na te nowe przestrzenie w ewoluującym ekosystemie Google.
Bo z Google jest trochę jak z flegmatycznym rewolwerowcem napadającym na bank. Przychodzi z bronią, powoli, nie spieszy się, trochę postraszy, trochę pogada, poogląda, przymierza, znów postraszy… ale jak już strzeli to i tak zabije 🙂 Lepiej być na taki strzał gotowy, szczególnie, że Google daje nam na to bardzo dużo czasu.
Zaufali nam


Po przeczytaniu nasuwa mi się jeden wniosek, że coraz szybciej zbliżamy się do końca SEO jakie znamy. Może już jesteśmy na końcówce „klasycznych” działań? Mi się tak właśnie wydaje, że za 5 lat będzie ciężko coś ugrać ofertą na lynki + średnie CM. Z drugiej strony jaki to będzie miało wpływ na branże ecommerce? Tutaj jest więcej pytań niż odpowiedzi.