

I have not been here for a long time, because I have been busy, surprisingly, doing SEO. I’m interrupting this workaholic trance interspersed with online linkbuilder concrete crap to come back and address the topic of entities in SEO in a bit more detail.
A year ago, I wrote quite a bit about MREID – the fact that everything in Google’s eyes has a number. Including diseases, historical events, people, brands, etc. etc.
The article, while focusing on the MREID itself (which has since solidified in the documentation under the more succinct acronym mid) is really talking about the entities themselves after all – the IDs given by Google are just the entities’ call-code.
So what is the concept of entity in SEO?
How to translate the word entity?
Entity is simply a unit, an entity in English. There is probably no better translation for this word than the literal ones.
Even more precise is the unit of knowledge.
Although there is still surprisingly little talk about the subject of entities, I have already encountered the translation of entities as entities.
Although in some areas of computer science this translation is used precisely for certain units of knowledge, it is also used, for example, in character encoding (HTML entities), and this can get a little mixed up.
Well, in time, language users will choose for themselves the most convenient form.
Spis treści
What are Entities in SEO?
Knowledge units are actually the best term for entities both semantically and substantively. This is because they are such structured scopes of knowledge that describe a single element.
It can be:
- person
- football team
- weather phenomenon
- scientific theory
- milestone
- company
- product
- video
- color
- planet
- date
- law of physics
- chemical element
- disease
- etc.
As we can see, the unit of knowledge can be anything that can be described in a structured way, such as.
Nazwa: FC Barcelona Rodzaj: drużyna piłkarska; profesjonalna drużyna sportowa; klub sportowy Data powstania: 29-11-1899 Pełna nazwa: Futbol Club Barcelona Kraj: Hiszpania Stadion: Camp Nou Sport: piłka nożna
Google records each unit of knowledge with different types of data:
- name
- ID (in the article from a year ago I write about MREID, in the API it appears mid – call it what you will)
- class – in short: what an object is, such as a movie.
- Attribute – e.g., the number of minutes of the movie, release date
- Relationship – the way in which an object is related to another unit of knowledge (e.g. Pulp Fiction and Quentin Tarantino are related by the Director relationship).
- relevance – an assessment of the relevance of a given link, e.g. black is at 0.99 color, but is Pulp Fiction surely a comedy?
Importantly, in most cases, units of knowledge are described with the help of other units of knowledge, e.g. the enitity of Pulp Fiction as a director recorded has entity Quentin Tarantino.
While this is a simple definition, this approach to information gathering, based on structured data rather than simple strings of characters, raises incredible implications.
Why is entity oriented search revolutionizing information retrieval?
In the beginning was the word. Google in its old-school version had text available. Hired from millions of different websites, robots, like medieval monks, memorized, transcribed and copied the texts.
These monks, i.e. our robots and Google servers, could not remember all the rewritten and copied books. So the text was stuck on the shelves in large libraries.
When a user performed a search, such as looking for information on a quarter-inch harvester trellis, none of the monks could answer him, because monks don’t know about quarter-inch harvester trellises. The monks were only able to find a book on harvesters in the library, a book on trellises and in both of these books look for something about quarter-inch elements.
The development of the search engine was only that the monks searched for information faster and faster, catalogued it more and more wisely, judged the quality of the books in which to look for information, and arranged them more and more wisely on the shelves so that they would be easier to find later. Just that and so much more.
And here the analogy with medieval scribes ends, because suddenly there was a revolution of sorts. Entity Oriented Search, and in general the very idea of gathering information not as a collection of texts, but clusters of structured knowledge, has changed search irrevocably. It has made Google’s database now an all-inclusive, self-sufficient book, with only references to other books in the footnotes. But that’s not all.
Google acquired Freebase in 2010, and now continues to develop it in Knowledge Graphs, even making some of it available through APIs. This gives us insight into what Google already knows. And he knows plenty, and this is also evident in the SERP on a daily basis:
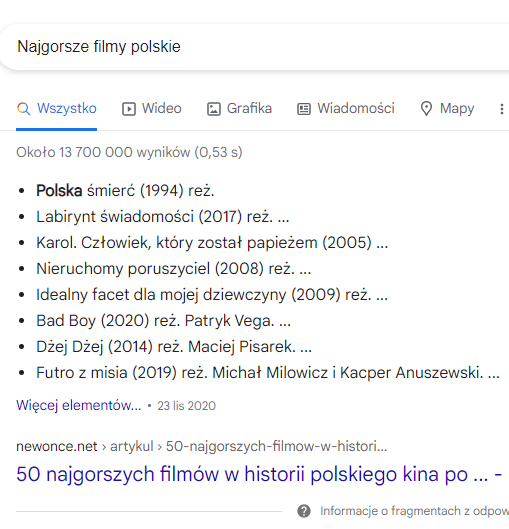
Above we see an example of the old approach to information retrieval. Google, considering a number of ranking factors, judged that this particular article would be the most appropriate. OK, we are not discussing the quality of the results now, just the way they are selected and presented.
Google’s choice was this article for many reasons, but most of them are based on the rationale behind the text string. Google has not presented us with this example that it understands the issue, we don’t even know that it knows it’s about movies. Perhaps he knows, perhaps he doesn’t, it’s hard to say.
What’s more, he emphasized the word Poland, indicating that simply this result seemed important to him, even though it makes no sense to our inquiry.
Now for the contrast:
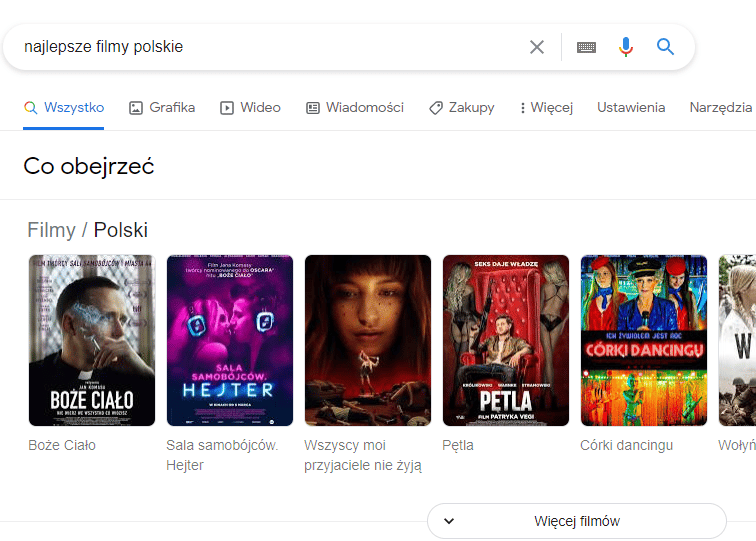
Here the snippet is already based on specific units of knowledge. Google does not offer a string of characters as a response to a query, but specific movie suggestions.
He chose them because the knowledge unit contains information that the film is Polish and that it has the best reviews.
Of course, after clicking on them, we have comprehensive information about each of the videos:
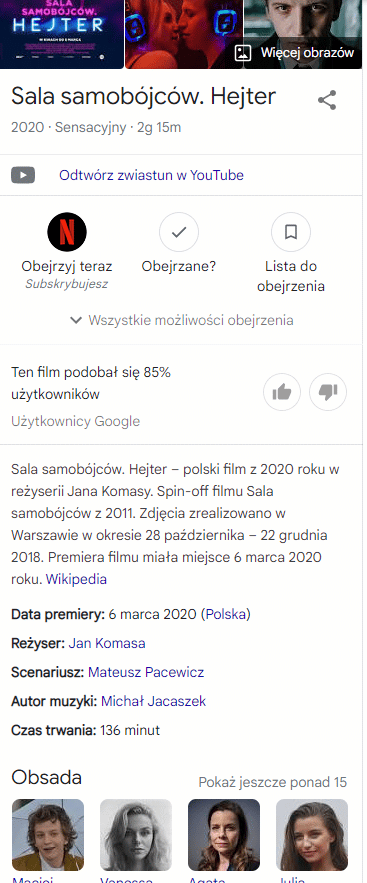
From just this one example, we learn the four absolute most important lessons from the impact of entities on search:
First: this approach forces you to look for another way to avoid zero click searches
Today I don’t want to focus on that, but the conclusion is simple: you can spend multi-digit budgets on Whitepress, but still Top 1 for these types of phrases can be a risky investment due to zero click searches. Let’s face it: for many industries, it’s time to create a strategy to appear here where we see Netflix in the graphic above, instead of spending fabulous sums targeting the top 10. You can spell reality, but you can’t do it indefinitely. Amen.
Second: the presentation of data is changing
A trivial and obvious conclusion, but is it obvious what the consequences are? And these are quite extensive, because, for example:
- A complete change in the way information is searched in anticipation of a different search result than before (bye-bye, long tails),
- Changing the way information is consumed from more extensive textual forms to dry facts and summaries in the form of short snippets,
- A complete redefinition of the very nature of the search process.
By the latter, I mean a change from an inbound model to something much more extended. For here, a user searching for information about a film immediately receives a picture of the director and the entire cast, an invitation to watch the film, to watch the trailer, to further search for related information, and so on.
So the classic search engine model of inbound marketing, in which it is the user who comes and calls up the content at his own request, is expanding – now it is the content that comes to the user, who barely has time to express interest in it. It is no longer just a small box of People Also Ask.
Third: the strength of knowledge units lies primarily in the relationships between them
What would entities be if Google didn’t understand how they are interrelated? I guess it is in the relationship between them that the whole strength of the idea lies.
Imagine such a collection of knowledge units:
Nazwa: Adam Mickiewicz Zawód: pisarz Kraj: Polska Miejsce urodzenia: Nowogródek Miejsce śmierci: Konstantynopol Wykształcenie: Uniwersytet Wileński Nazwa: Józef Ignacy Kraszewski Zawód: pisarz Kraj: Polska Miejsce urodzenia: Warszawa Miejsce śmierci: Genewa Wykształcenie: Uniwersytet Wileński
If Google did not understand the relationship between these units of knowledge, it would only be possible to obtain simple information, such as:
Zapytanie: polski pisarz urodzony w Nowogródku Odpowiedź: Adam Mickiewicz
or
Zapytanie: sławni absolwenci uniwersytetu wileńskiego Odpowiedź: Adam Mickiewicz;Józef Ignacy Kraszewski
However, it is only by understanding the relationships between knowledge units, and further analyzing them, that we are able to perform such a query:
Zapytanie: sławni Polscy pisarze zmarli poza Polską Odpowiedź: Adam Mickiewicz;Józef Ignacy Kraszewski
The key to the success of such a query, is that the data about each entity is not only structured, but also linked.
The fact that our sample characters are Polish, writers, and that they graduated from the University of Warsaw is a direct result of the data.
The fact that they died outside Poland is due to the fact that in the passage:
Miejsce śmierci: Genewa
…Geneva is not a mere string of characters, but a separate unit of knowledge.
So Google not only knows that Kraszewski died in Geneva. Google knows that Kraszewski died in Geneva, which is a city in Switzerland (not Poland), 200,000 population, capital of the canton of Geneva, official French language, etc…. That Mickiewicz died in Constantinople, which is the historical name of Istanbul, and that this is in Turkey.
This completely changes the character of things; understanding the relationships between the various entities opens up further untold layers of knowledge and access to data.
Fourth: it is not obvious what is and what is not a ranking factor
Let’s assume that we will somehow manage to take a bite out of this cake.
Using the film industry example further, we will manage to jump into the knowledge graph with our site as an integral part of the knowledge of a particular film.
What now? Well, somehow you have to make sure that, since we are there, we appear as often as possible. Is it possible to position knowledge units?
In theory, yes, especially in niches where Google has fewer signals and sources to collect knowledge – so they are easier to manipulate.
How to do it – this will probably already be described to you in a few years by all sorts of specialists, as they awaken: content, structured data and God knows what else.
And I would just like to point out a problem.
If SEO in a decade or so will be about “jumping into” knowledge graphs and promoting them*, then what we know today as ranking signal will lose its meaning.
Because what will be the meaning of our efforts if for the phrase:

… the biggest impact will be:
… … and that’s something we’re unlikely to jump over.
To put it simply: today, on the question of whether the coming Sunday is commercial some specialists can write a new dissertation every week. But soon only one answer will be possible to the question of whether 2 + 2 equals 4.
Dry facts will prevail over positioning combinations. Great news for users, a little worse for us 🙂
* It’s actually not a stupid idea. Could this be what the SEO of the future could consist of, that for each product, thing or service being promoted, something like a knowledge graph will be created and it will only need to be polished and possibly supplemented with data? This sounds quite realistic, but of course this is just fortune-telling.
How Google dealt with the biggest problem with Entity Oriented Search
I first introduced the analogy of Google’s original technology, comparing the bots to medieval monks writing down and organizing texts in books.
Today, Google is such a super-brain that the most important knowledge from these books has already been assimilated and has instant access to it.
Two problems remain.
The first is that still very, very much of this knowledge remains recorded only in books. This is because Google easily assimilated knowledge that was systematized, somehow structured. What remains is a vast amount of knowledge scribbled in manuscripts, strange languages, unreadable.
So we have a bit of a bifurcation in the database – on the one hand, Google has a state-of-the-art database of entities that it can rearrange, combine and adapt to a query, and on the other hand, a huge, unstructured collection of texts in which it searches with greater or lesser efficiency for answers to questions asked by users. And I suspect that the latter type of dataset, is in most languages (including Polish) much larger in volume than the former.
And this is not even the most important problem – such coexistence of these different types of data has been going on for a long time and the world has not collapsed.
Google’s most important problem is The combination of these resources into a whole. Mapping structured with unstructured knowledge. And that’s exactly what’s happening: before our eyes, more and more phrases and queries will receive their knowledge graphs, elaborate snippets, or simply instant data-driven answers.
There is, of course, only one answer to the question of how Google does it: artificial intelligence. However, such trivial answers satisfy no one, so I decided to take a closer look at the issue.
What the Cloud Natural Language API tells us
Where do you look for information about what Google is working on and what will be trending in SEO in the coming years?
- Google press releases and their blogs?
- Documentation of promoted projects (e.g., AMP)?
- industry blogs?
- Your own intuition?
- Google’s patents?
All very good ways, especially if you sift out the strictly PR activities and spend most of your time studying patents.
However, there is another tip that is often overlooked, and that is the APIs and their documentation.
For our topic, it would be most appropriate to deal with the Knowledge Graph Search API, through which we can search for data on some knowledge units.
I highly recommend playing with this marvel, but I’m not about that today.
Let’s focus on the Cloud Natural Language API. It is a service that allows the use of artificial intelligence to understand content based on pure text alone.
Here’s how much Google can already do. On pure text alone, the API can perform:
- Sentiment analysis – evaluation of the main emotion accompanying the text, focusing on the poles: positive, neutral, negative.
- Entity analysis – “extracts” and recognizes all recognized entities from the text
- Entity sentiment analysis – extracts all recognized entities from the text and returns info on the emotions in which they are referred to (positive, neutral, negative)
- Syntactic analysis – divides text into sentences and/or tokenizes, then returns context information for sentences/tokens
- Content classification – gives content a category.
So here we have a tool that extracts units of knowledge from a simple text. For example, the sentence:
President Trump will speak from the White House, located at 1600 Pennsylvania Ave NW, Washington, DC, on October 7.
… Returns:
{
"entities": [
{
"name": "Trump",
"type": "PERSON",
"metadata": {
"mid": "/m/0cqt90",
"wikipedia_url": "https://en.wikipedia.org/wiki/Donald_Trump"
},
"salience": 0.7936003,
"mentions": [
{
"text": {
"content": "Trump",
"beginOffset": 10
},
"type": "PROPER"
},
{
"text": {
"content": "President",
"beginOffset": 0
},
"type": "COMMON"
}
]
},
{
"name": "White House",
"type": "LOCATION",
"metadata": {
"mid": "/m/081sq",
"wikipedia_url": "https://en.wikipedia.org/wiki/White_House"
},
"salience": 0.09172433,
"mentions": [
{
"text": {
"content": "White House",
"beginOffset": 36
},
"type": "PROPER"
}
]
},
{
"name": "Pennsylvania Ave NW",
"type": "LOCATION",
"metadata": {
"mid": "/g/1tgb87cq"
},
"salience": 0.085507184,
"mentions": [
{
"text": {
"content": "Pennsylvania Ave NW",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
{
"name": "Washington, DC",
"type": "LOCATION",
"metadata": {
"mid": "/m/0rh6k",
"wikipedia_url": "https://en.wikipedia.org/wiki/Washington,_D.C."
},
"salience": 0.029168168,
"mentions": [
{
"text": {
"content": "Washington, DC",
"beginOffset": 86
},
"type": "PROPER"
}
]
}
{
"name": "1600 Pennsylvania Ave NW, Washington, DC",
"type": "ADDRESS",
"metadata": {
"country": "US",
"sublocality": "Fort Lesley J. McNair",
"locality": "Washington",
"street_name": "Pennsylvania Avenue Northwest",
"broad_region": "District of Columbia",
"narrow_region": "District of Columbia",
"street_number": "1600"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "1600 Pennsylvania Ave NW, Washington, DC",
"beginOffset": 60
},
"type": "TYPE_UNKNOWN"
}
]
}
}
{
"name": "1600",
"type": "NUMBER",
"metadata": {
"value": "1600"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "1600",
"beginOffset": 60
},
"type": "TYPE_UNKNOWN"
}
]
},
{
"name": "October 7",
"type": "DATE",
"metadata": {
"day": "7",
"month": "10"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "October 7",
"beginOffset": 105
},
"type": "TYPE_UNKNOWN"
}
]
}
{
"name": "7",
"type": "NUMBER",
"metadata": {
"value": "7"
},
"salience": 0,
"mentions": [
{
"text": {
"content": "7",
"beginOffset": 113
},
"type": "TYPE_UNKNOWN"
}
]
}
],
"language": "en"
}
What’s the odtrump here? Based on a single sentence with the help of the API, we established the language, determined who the text was about, what function this someone has, where they will be, the name of the place and its exact address.
And these are not data detached from reality. We can use the ID to further assign them and combine different texts into a single block of meaning.
Ba, not much. If we had added, for example, at the beginning of the sentence. “Our beloved master President Trump…” and instead of using the analyzeEntities method they used the analyzeEntitySentiment method then additionally Google would still evaluate our attitude towards Trump (and by the way a neutral attitude towards Pennsylvania Avenue, the White House and the date of October 7 😉 ).
Google can already do so much, and let’s remember that this is a publicly shared technology. What is going on “under the hood” and what new abilities to categorize and better understand text are already being tested – we don’t know.
It is therefore a matter of time to systematize all the knowledge Google has access to – and over time this process can only accelerate.
All right, but what’s next?
Well, nothing. This is a revolution that has been going on slowly, but it has been going on for quite a long time. There has been so much going on in the topic that I decided to put it together and discuss it focusing on the reasons rather than the symptoms.
And what these symptoms are, it probably doesn’t need to be explained to anyone anymore: 65% of searches not completing a click in 2020. I could paste screenshots here showing the impact of Google’s focus on entities on such a state of affairs, but since you have reached this part of the article, you are probably well aware of this.
Although Entity Oriented Search turns all previous SEO dogma on its head, specialists will certainly try to tap into units of knowledge so that in some way their clients are part of them (I’m already trying, but without techniques from under the dark hat, it’s not easy 😉 ). Conservatives will pour over the issue until the last minute. And I think let’s do our own thing, but in the back of our minds let’s have a plan, some strategy that will eventually allow us to break into these new spaces in Google’s evolving ecosystem.
Because with Google it’s a bit like a phlegmatic gunman robbing a bank. He comes with a gun, slowly, not in a hurry, he scares a little, talks a little, looks, tries it on, scares again…. but once he shoots, he will still kill 🙂 It’s better to be ready for such a shot, especially since Google gives us a very long time to do it.
They trusted us

